Les sanctions manuelles de Google pour abus de réputation de site peuvent avoir des conséquences désastreuses sur votre visibilité. Pourtant, de nombreux webmasters utilisent encore des méthodes inefficaces pour bloquer le contenu jugé problématique. Dans cet article, découvrez quelles sont les méthodes les plus efficaces, et celles à mettre de côté, pour éviter les sanctions.
Ce qu’il faut retenir :
- Google continue d’utiliser des actions manuelles pour gérer l’abus de réputation de site, plutôt qu’une approche purement algorithmique.
- Les deux seules méthodes efficaces pour bloquer le contenu problématique sont l’utilisation d’une balise noindex ou la suppression complète du contenu.
- Bloquer via robots.txt ou canonicaliser le contenu sont des méthodes inefficaces qui peuvent conduire à l’indexation et au classement du contenu.
- Google a récemment mis à jour sa documentation pour clarifier l’utilisation du noindex.
Qu’est-ce que l’abus de réputation de site selon Google ?
Avant de plonger plus en détails dans les solutions techniques, rappelons que l’abus de réputation de site, ou parasite SEO, concerne du contenu qui profite injustement de la réputation d’un domaine, mais qui est très différent du contenu principal du site.
Google a développé des systèmes pour identifier ces sections de contenu « indépendantes ou très différentes » du contenu principal. Bien que Google puisse théoriquement utiliser ces systèmes comme base pour traiter automatiquement l’abus de réputation de site, l’entreprise continue d’appliquer principalement des actions manuelles pour éviter les dommages collatéraux qu’un algorithme pourrait causer.
Récemment, Google a déployé une série d’actions manuelles en Europe ciblant ce type d’infraction. Si vous voulez éviter de faire les frais de la politique de la firme de Mountain View, il vous reste à lire ce qui suit !
Les méthodes inefficaces pour bloquer le contenu problématique
Bloquer le contenu avec le robots.txt
Contrairement à ce que pensent de nombreux propriétaires de sites, bloquer du contenu via le fichier robots.txt n’est pas une approche valide pour traiter une action manuelle pour abus de réputation de site. Voici pourquoi :
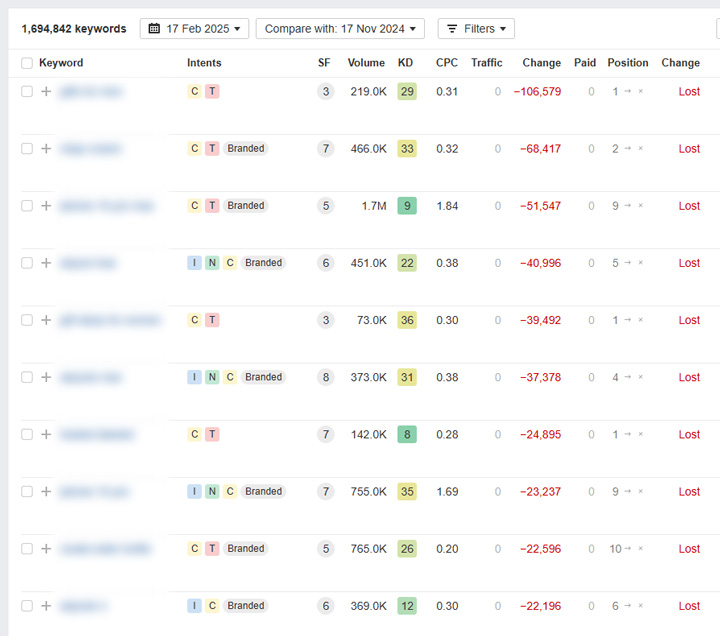
- Les pages bloquées par robots.txt peuvent toujours être indexées et classées, Google ne peut simplement pas explorer leur contenu.
- Cette méthode n’est valable que pour les images et les vidéos, pas pour les documents HTML, en particulier en cas d’existence de backlinks.
- Google ne recommande pas cette approche dans sa documentation officielle.
Un exemple concret : un site a récemment vu sa visibilité chuter après avoir reçu une action manuelle. Le site a commencé à la fois à appliquer un noindex sur le contenu ET à le bloquer via robots.txt. Le problème ? Google ne pouvait pas explorer les URLs pour identifier la présence d’une balise noindex. Résultat : les pages sont restées indexées et ont continué à bien se classer dans les résultats de recherche. Oups !
En outre, le 12 mars 2025, Google a mis à jour sa documentation officielles sur les actions manuelles en précisant clairement : « Pour vous assurer que votre règle noindex soit efficace, ne bloquez pas ce contenu avec votre fichier robots.txt. »
Canonicaliser le contenu problématique
Cette approche n’est pas non plus recommandée par Google. Certains sites canonicalisent les URLs qui enfreignent la politique d’abus de réputation vers le répertoire de niveau supérieur ou vers d’autres URLs.
Il faut comprendre que la balise rel=”canonical” est seulement une indication, et non une directive. Google peut donc délibérément choisir d’ignorer la canonicalisation définie et indexer les URLs problématiques, qui peuvent alors se classer dans les pages de résultats.
Un exemple ? Un site puissant possède un répertoire entier de contenu enfreignant la politique d’abus de réputation. Toutes les URLs de ce répertoire sont canonicalisées vers une autre URL… qui renvoie une erreur 404. Malgré cela, Google a indexé les URLs du répertoire qui se classe sur plus de 50 000 requêtes. Re-Oups !
Les méthodes efficaces pour bloquer le contenu problématique
Ajouter une balise noindex
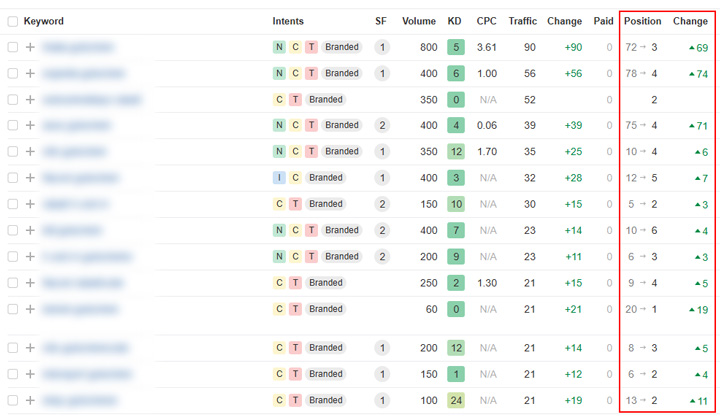
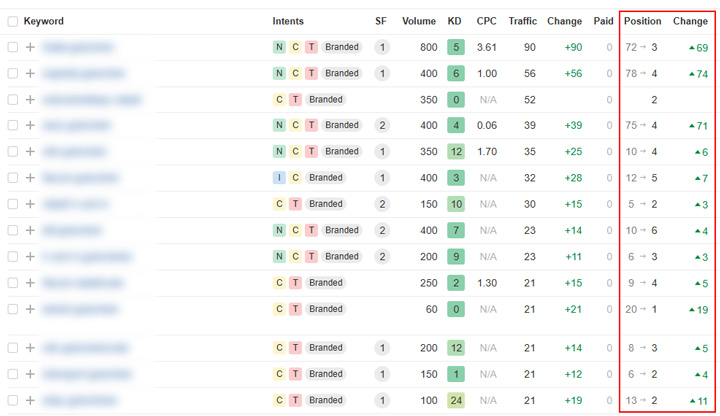
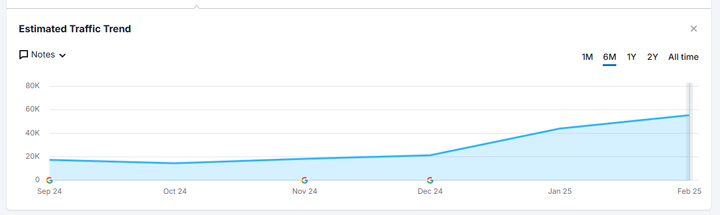
Si vous utilisez noindex sur le contenu, Google réexplorera les URLs puis les supprimera de l’index. Une fois retirées de l’index, elles ne peuvent plus se classer. Noindex est une directive, pas une simple indication. Vous n’avez donc pas à vous inquiéter de savoir si Google va la suivre ou non. Une fois que Google réexplore l’URL et voit la balise noindex, la page est retirée de l’index.
Important : n’utilisez pas à la fois noindex ET un blocage via robots.txt. Comme expliqué précédemment, cela peut conduire à ce que les URLs restent indexées sans que Google puisse explorer leur contenu.
Un exemple de réussite : un site a correctement appliqué noindex à tout le contenu d’un répertoire qui enfreignait la politique de Google. Après avoir soumis une demande de réexamen, l’action manuelle a été levée. La visibilité a brièvement augmenté, le temps que Google réexplore toutes les URLs, puis a fortement diminué à mesure que Google supprimait les pages de l’index.
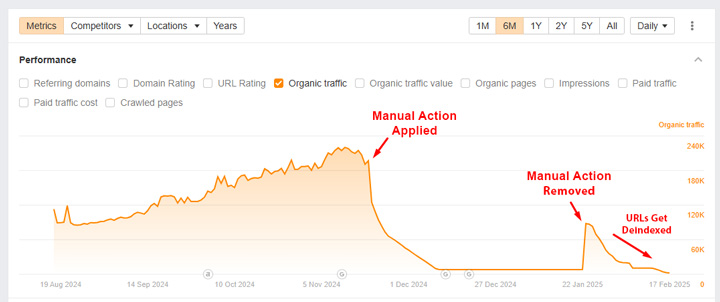
Supprimer complètement le contenu (erreurs 404 ou 410)
Cette solution est aussi simple que radicale : si vous supprimez complètement le contenu ou le répertoire contenant les pages problématique, celui-ci ne peut évidemment plus se classer dans les résultats de recherche. Forcément, ça fonctionne !
Cependant, il ne faudrait pas oublier qu’il exister d’autres sources de trafic en dehors de Google. C’est pourquoi certains sites choisissent d’utiliser noindex uniquement pour Google et pas pour les autres moteurs. Vous pourriez choisir de diriger les utilisateurs vers ces contenus via la publicité, les médias sociaux, ou des CTA une fois que les utilisateurs sont sur votre site.
Un exemple : un site a supprimé tout le contenu d’un répertoire qui allait à l’encontre de la la politique d’abus de réputation, ce qui a entraîné une chute massive du classement au fil du temps, à mesure que Google détectait les erreurs 404.