La promesse a fait l’effet d’un pavé dans la mare : X annonce l’ouverture d’une partie de son algorithme de recommandation, y compris une brique liée au publicitaire, sous licence open source. Dans un climat où la transparence est devenue un mot d’ordre — autant pour les citoyens que pour les régulateurs — la décision s’inscrit dans une séquence tendue : amende européenne, critiques sur les biais, soupçons d’extraction abusive de données et exigence d’accès pour la recherche. L’idée, sur le papier, est puissante : permettre à des développeurs indépendants, à des universitaires et à des ingénieurs concurrents d’observer la mécanique et de proposer des correctifs, alors que l’intelligence artificielle pilote désormais l’essentiel de la distribution de contenu.
Mais la vraie question n’est pas seulement “le code sera-t-il visible ?”. Elle est plutôt : qu’est-ce que cette visibilité va réellement changer pour l’utilisateur, l’annonceur, et le marché du marketing digital ? Entre ce qui est publié sur un dépôt et ce qui tourne en production, il y a les réglages, les seuils, les modèles entraînés, les garde-fous, et les arbitrages commerciaux. Ce partage peut déclencher une vague d’innovation, tout en donnant aux attaquants de nouvelles cartes pour contourner les protections. Et si l’opération est répétée toutes les quatre semaines, comme promis, elle peut transformer la gouvernance des plateformes en feuilleton technique, suivi par une communauté qui ne pardonne pas l’approximation.
Algorithme publicitaire de X en open source : ce que l’ouverture change vraiment
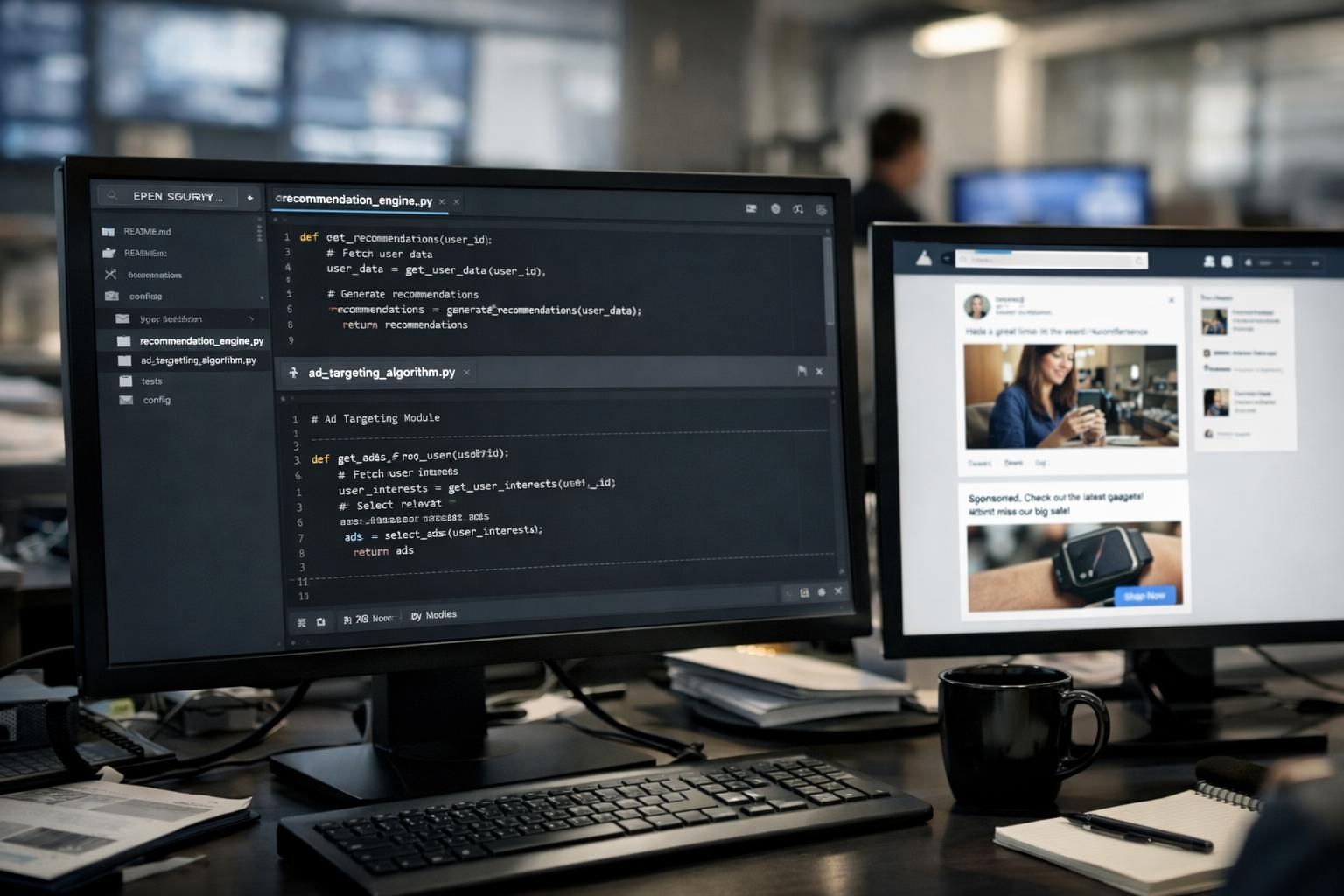
Quand une plateforme parle d’ouvrir son algorithme, il faut d’abord comprendre le périmètre. Dans le cas de X, l’annonce évoque le code de recommandation des contenus organiques et une partie des mécanismes utilisés pour la diffusion publicitaire. Ce détail est décisif : la recommandation organique façonne l’attention, et l’attention conditionne la valeur publicitaire. Autrement dit, toucher au moteur de classement revient à toucher à l’économie interne de la plateforme.
Sur le plan technique, un système de recommandation moderne s’appuie sur des modèles d’intelligence artificielle qui classent, filtrent et ordonnent des publications en fonction de signaux multiples : interactions, vitesse d’engagement, relation avec l’auteur, qualité perçue, probabilité de clic, et signaux négatifs (masquages, signalements). Dans un contexte publicitaire, les signaux incluent aussi la compatibilité annonce-audience, la fatigue publicitaire, et des contraintes de sûreté de marque. Ouvrir le code, c’est dévoiler des choix : quels signaux comptent, comment ils sont pondérés, et à quel moment la règle métier l’emporte sur le modèle.
Pour illustrer les effets concrets, prenons une entreprise fictive, Atelier Nébula, une marque qui vend des accessoires tech et dépend de X pour faire connaître ses lancements. Si le code open source montre qu’un type d’interaction (par exemple “enregistrer” ou “partager”) pèse plus lourd que le “like”, l’équipe marketing peut adapter sa création : inciter au partage par une offre limitée, ou produire des formats explicatifs plus propices à l’enregistrement. Dans le marketing digital, ce niveau d’information change la manière de concevoir les campagnes, un peu comme lorsque les professionnels ont appris à composer avec l’évolution de la recherche assistée par IA, décrite dans les nouveaux usages de l’IA générative dans la recherche web.
Le bénéfice revendiqué est la transparence : la communauté peut auditer, signaler des biais, proposer des correctifs, ou vérifier si certaines catégories sont systématiquement défavorisées. Cependant, l’ouverture ne dit pas tout. Les modèles peuvent rester fermés (poids, datasets), et surtout les paramètres “live” peuvent évoluer quotidiennement. On peut publier une architecture exemplaire et modifier les seuils en production sans que le dépôt ne raconte l’histoire complète. La valeur dépendra donc de la discipline de publication, de la qualité des notes de version, et de la fidélité entre code public et code exécuté.
Cette tension est déjà visible dans d’autres secteurs où l’IA structure la décision, qu’il s’agisse de pricing ou de performance. Les débats autour des systèmes de tarification automatisée, par exemple, montrent qu’un mécanisme peut être “compréhensible” en théorie tout en restant imprévisible à l’usage : les prix dynamiques en e-commerce pilotés par IA en sont une illustration. Sur X, la conséquence est similaire : un algorithme publié peut être lisible, mais l’expérience réelle dépendra de l’entraînement, des garde-fous et des arbitrages commerciaux. Insight final : l’open source ne vaut pas seulement par la visibilité du code, mais par la capacité à relier ce code à des comportements observables.

Transparence, régulation et confiance : X face aux exigences européennes
L’ouverture partielle de l’algorithme intervient dans un environnement réglementaire plus exigeant qu’il y a quelques années. L’Union européenne a renforcé son arsenal via le Digital Services Act, en demandant davantage de transparence sur les systèmes de recommandation, sur les bibliothèques publicitaires et sur l’accès des chercheurs aux données publiques. Dans ce contexte, la plateforme a subi une amende notable — 120 millions d’euros — liée à des manquements perçus : fonctionnement du “badge bleu”, registre publicitaire jugé insuffisant, et accès trop limité pour l’analyse indépendante.
Pour les régulateurs, l’objectif est double. D’une part, comprendre comment une plateforme amplifie des contenus, y compris ceux qui peuvent être illégaux. D’autre part, réduire l’opacité des mécanismes qui transforment l’attention en revenus. La prolongation d’une ordonnance de conservation jusqu’à fin 2026 liée aux algorithmes et à la diffusion de contenus illicites illustre la pression : les autorités veulent pouvoir reconstituer la chaîne de décisions, pas seulement lire un manifeste de bonnes intentions.
Dans la pratique, la transparence algorithmique se heurte à un paradoxe : trop d’informations peuvent favoriser la manipulation. Si les règles exactes de ranking sont connues, des acteurs malveillants peuvent optimiser des campagnes de spam, créer des réseaux de comptes ou détourner les signaux d’engagement. L’open source doit donc s’accompagner d’une gouvernance : publication du code “structurel”, mais protection des seuils sensibles, documentation des mécanismes anti-abus, et procédures de divulgation responsable des failles. Cette logique ressemble à ce qui s’est produit dans la publicité en ligne lorsque des filières de fraude ont exploité des zones grises : l’écosystème a dû muscler contrôles et audits, comme l’illustre l’affaire des publicités frauduleuses sur les plateformes sociales.
La confiance ne se répare pas uniquement avec du code. Pour l’utilisateur, ce qui compte, c’est l’impression de contrôle : pourquoi vois-je ce post, pourquoi cette annonce, pourquoi ce compte revient-il malgré mes préférences ? Une ouverture bien faite peut permettre la naissance d’outils tiers : extensions qui expliquent les facteurs probables de recommandation, tableaux de bord personnels, ou visualisations d’exposition. On a déjà vu ces dynamiques émerger dans le SEO et l’édition, où des solutions externalisées simplifient des règles de plus en plus complexes : les plugins SEO dopés à l’IA sur WordPress répondent à une demande comparable de lisibilité et d’assistance.
Pour Atelier Nébula, la dimension régulatoire est aussi commerciale. Une marque hésite à investir si elle craint un environnement instable, des changements de règles imprévisibles, ou une association à des contenus toxiques. La publication régulière (toutes les quatre semaines, annoncée avec notes détaillées) peut rassurer : elle transforme une “boîte noire” en produit maintenu publiquement, avec un calendrier et une responsabilité visible. Insight final : la régulation pousse à ouvrir, mais seule une transparence opérable — compréhensible et actionnable — restaure durablement la confiance.
Observer ces enjeux dans une perspective plus large aide à comprendre pourquoi l’annonce résonne autant : les tendances IA présentées chaque année structurent déjà les attentes du marché, comme on le voit dans les technologies IA marquantes au CES 2026, où l’auditabilité et la sécurité deviennent des critères de vente autant que des sujets politiques.
Dans le marketing digital, l’accès à des éléments de l’algorithme n’est pas une curiosité d’ingénieur : c’est un avantage stratégique. Les annonceurs cherchent à réduire l’incertitude, à stabiliser leurs coûts d’acquisition, et à comprendre la logique de distribution. Si X publie des éléments du moteur publicitaire, cela peut modifier les pratiques, notamment sur la création, le ciblage, la mesure et l’orchestration multi-canal.
Premier effet attendu : une amélioration de la “créa” guidée par des signaux mieux compris. Si les facteurs de qualité (pertinence, expérience post-clic, taux de masquage, répétition) sont documentés, les équipes peuvent concevoir des annonces qui “vivent” mieux dans le flux. Atelier Nébula, par exemple, pourrait tester deux formats : une annonce produit classique, et une annonce démonstrative en mini-tutoriel. Si le code suggère qu’un signal de “temps de lecture” ou de “complétion vidéo” influence le classement, l’annonce tutorielle peut devenir prioritaire. Ce raisonnement ressemble à l’évolution observée sur les plateformes publicitaires dopées à l’IA, où l’optimisation créative devient centrale : panorama des plateformes publicitaires basées sur l’IA.
Deuxième effet : un regain d’expérimentation. Les annonceurs disposent souvent d’API et d’outils, mais ils manquent du “pourquoi” derrière les résultats. Avec des éléments open source, des analystes peuvent construire des simulateurs : estimer l’impact d’un changement de fréquence, d’un élargissement d’audience, ou d’une variation de budget. Bien sûr, la simulation ne remplacera pas la réalité (le système est dynamique), mais elle permet de mieux formuler les hypothèses et de rationaliser les tests A/B.
Troisième effet : une pression accrue sur la mesure. Lorsque le code indique quels événements comptent, les annonceurs veulent vérifier que leurs balises et leurs événements sont correctement enregistrés. Cela rapproche la publicité sociale des exigences e-commerce déjà très instrumentées. Un commerce qui utilise des outils automatisés cherchera à connecter ses signaux (catalogue, stocks, conversions) avec les logiques d’enchères. Les marques qui opèrent sur Shopify ont déjà cette culture de la donnée outillée, décrite dans les outils marketing clés sur Shopify.
Pour rendre ces enjeux plus concrets, voici une liste de leviers que les équipes peuvent activer si la documentation open source est suffisamment précise :
- Aligner les créations sur les signaux favorisés (ex. complétion vidéo, partages, commentaires de qualité) et éviter les motifs associés au masquage.
- Renforcer la qualité des pages d’atterrissage si le moteur prend en compte des signaux post-clic (vitesse, clarté, taux de rebond).
- Segmenter la fréquence par cohortes pour limiter la fatigue publicitaire, au lieu d’augmenter mécaniquement les impressions.
- Documenter les exclusions (brand safety, contenus sensibles) afin d’éviter que les campagnes se retrouvent à côté de discussions à risque.
- Mettre en place un “change log” interne synchronisé avec les mises à jour toutes les quatre semaines pour relier variations de performance et modifications du code.
Ce mouvement s’articule avec un autre phénomène : la recherche et la découverte se déplacent, et les marques doivent composer avec des parcours fragmentés (social, moteurs, places de marché). La baisse de visibilité organique sur certains espaces a déjà forcé les équipes à redéfinir leurs budgets, comme on l’observe avec la baisse du CTR liée aux AI Overviews. Insight final : si X publie assez pour rendre les signaux actionnables, l’avantage ira aux équipes capables de transformer la transparence en protocole de test.
Ce que révèle le code : apprentissage profond, biais, données et audit externe
Lorsqu’un code devient open source, l’enjeu n’est pas uniquement la lecture, mais l’interprétation. Les systèmes modernes d’intelligence artificielle combinent des couches : collecte de données, featurisation, modèles de scoring, règles de filtrage, et mécanismes de contrôle. Publier une partie de l’algorithme permet de poser de meilleures questions : quelles variables entrent en jeu, comment les erreurs sont gérées, et quels garde-fous empêchent les dérives.
Pour rendre cela intelligible, on peut distinguer trois niveaux d’audit. Niveau 1 : audit de code (qualité, robustesse, sécurité, logique). Niveau 2 : audit de conception (quels objectifs optimise-t-on : clic, temps passé, satisfaction déclarée, diversité ?). Niveau 3 : audit d’impact (quels effets sur les communautés, la polarisation, la visibilité de certains sujets ?). L’ouverture aide surtout sur les niveaux 1 et 2, et seulement partiellement sur le niveau 3, car l’impact dépend des données d’entraînement et des paramètres opérationnels.
Le débat sur les biais est central. Un modèle peut amplifier des déséquilibres existants : surreprésentation de certains types de contenus, visibilité accrue des messages clivants, ou avantage involontaire donné à des groupes organisés capables de générer de l’engagement artificiel. Pour Atelier Nébula, cela se traduit de façon prosaïque : une annonce sérieuse peut être moins diffusée qu’un contenu provocateur si l’optimisation favorise l’interaction brute. L’audit open source peut révéler si des signaux de “qualité” ou de “fiabilité” sont intégrés, et comment ils sont pondérés par rapport aux signaux d’excitation.
Le code peut aussi mettre en lumière les mécanismes anti-manipulation : détection de grappes, pénalités de répétition, filtres d’intégrité. Cela rejoint les préoccupations de surveillance et de productivité liées à l’IA, où l’on cherche un équilibre entre efficacité et dérives. Comprendre les systèmes de contrôle, sans tomber dans la surveillance intrusive, est un enjeu plus large discuté dans les débats sur IA, surveillance et productivité. Sur X, la question devient : quels contrôles protègent la plateforme, et lesquels risquent d’étouffer des usages légitimes ?
Pour clarifier les dimensions attendues d’un algorithme publié, un tableau aide à distinguer ce que l’open source peut apporter, et ce qu’il ne suffit pas à garantir :
|
Dimension |
Ce que l’open source rend vérifiable |
Ce qui reste difficile sans accès aux données/paramètres |
|---|---|---|
|
Type d’apprentissage |
Architecture, pipelines, logique d’entraînement et d’inférence |
Qualité des jeux de données, représentativité, nettoyage réel |
|
Adaptabilité |
Mécanismes de mise à jour, signaux utilisés, feedback loops |
Fréquence des ajustements en production, seuils changeants |
|
Transparence |
Règles de classement, filtres, priorités déclarées |
Écarts entre code publié et version déployée, configuration interne |
|
Impact sur l’engagement |
Fonctions d’optimisation (clic, temps, satisfaction) et arbitrages |
Effets sociétaux mesurés, externalités (polarisation, désinformation) |
Un autre point sensible est la reproductibilité. Si X publie le code mais pas les modèles ni les données, les chercheurs pourront comprendre l’intention, pas forcément reproduire le résultat. Certaines plateformes choisissent alors de fournir des “suites de test” anonymisées ou des environnements contrôlés, pour permettre un audit sans exposer des données personnelles. Ce serait cohérent avec l’exigence d’accès des chercheurs évoquée par les régulateurs, tout en limitant le risque de fuite.
Enfin, le code peut devenir un outil pédagogique : il crée un langage commun entre la plateforme, les chercheurs et les annonceurs. L’open source, dans ce cas, n’est pas qu’un geste politique : c’est une documentation vivante. Insight final : la valeur de l’ouverture dépendra de la qualité de l’audit possible, pas seulement du volume de fichiers publiés.

Risques, sécurité et gouvernance : maintenir l’innovation sans ouvrir la porte aux abus
Rendre une partie d’un algorithme open source n’est pas une fin, c’est un début. L’écosystème va tester les limites : certains contribueront pour améliorer la qualité, d’autres chercheront à comprendre comment contourner les protections. La première ligne de risque est la sécurité logicielle. Dès qu’un dépôt public existe, des yeux repèrent aussi les failles : dépendances vulnérables, erreurs de validation, surfaces d’attaque. Une plateforme qui monétise du publicitaire ne peut pas se permettre des brèches, car elles touchent à la fois l’intégrité du feed, la protection des données et la fiabilité des enchères.
Le second risque est l’“industrialisation du gaming”. Si des acteurs mal intentionnés déduisent que certains signaux sont très rémunérateurs (par exemple le ratio commentaires/impressions ou la vitesse d’engagement), ils peuvent fabriquer des fermes d’interactions ou automatiser des conversations. Cela concerne autant l’organique que la publicité, puisque des campagnes peuvent être conçues pour paraître “naturelles” et contourner les filtres. À l’échelle du commerce, cette capacité à manipuler les signaux existe déjà sur d’autres canaux : les places de marché et les comparateurs se protègent contre les stratégies opportunistes, comme analysé dans les guerres de prix sur les comparateurs. Sur X, l’équivalent est une guerre de signaux.
Le troisième risque est la gouvernance du partage. Si la communauté propose des correctifs, qui décide ? À quelle vitesse ? Avec quels critères ? Les projets open source robustes reposent sur des mainteneurs, une charte de contribution, des revues de code, des tests automatisés et une gestion des versions. Or, l’algorithme d’une plateforme sociale n’est pas un logiciel neutre : il porte des choix éditoriaux, économiques et sociétaux. Il faudra donc une gouvernance hybride, où l’on distingue clairement :
- Le socle technique (qualité, performance, sécurité), ouvert aux contributions standardisées.
- Les politiques de diffusion (règles, priorités, garde-fous), qui nécessitent une décision interne et une redevabilité externe.
- Les mécanismes de contrôle (anti-spam, anti-fraude), documentés sans dévoiler les détails exploitables.
Sur le plan opérationnel, la promesse de mises à jour toutes les quatre semaines est structurante. Elle peut éviter l’effet “coup” où un code est publié puis abandonné. Elle oblige aussi X à faire de la pédagogie : notes de version, explications des changements, et justification des arbitrages. Cela peut devenir un standard de marché : publier du code, oui, mais aussi publier la logique qui accompagne les changements.
Pour les acteurs du marketing digital, cette gouvernance aura un impact direct. Si les modifications sont fréquentes, l’optimisation doit devenir plus agile : surveillance des performances, tests continus, et adaptation des créas. Certaines tendances e-commerce montrent déjà cette nécessité d’orchestration en temps réel, notamment quand les parcours d’achat intègrent influence et social shopping : l’essor du social commerce et de l’influence shopping éclaire cette accélération des cycles.
Enfin, une dimension souvent sous-estimée est la culture interne. Ouvrir une partie du moteur expose les débats : pourquoi privilégier tel signal, pourquoi limiter telle catégorie, pourquoi ce compromis entre liberté d’expression et réduction des abus ? À mesure que la communauté s’empare du dépôt, chaque choix devient une discussion publique. Insight final : si X réussit, ce ne sera pas uniquement grâce au code, mais grâce à une gouvernance capable de concilier transparence, sécurité et rythme d’innovation.