

Les navigateurs d’IA sont le dernier résultat de l’évolution vers l’IA agentique. Ils peuvent résumer un contenu, comparer des produits, vérifier des articles, remplir des formulaires et même accomplir des tâches en plusieurs étapes avec une seule instruction. Il s’agit d’une amélioration considérable de la commodité par rapport à la navigation traditionnelle.
Mais pour atteindre ce niveau d’automatisation, les navigateurs d’IA introduisent un nouvel ensemble de compromis en matière de confidentialité, de contrôle et de sécurité que la plupart des gens n’ont pas eu à prendre en compte auparavant.
Par rapport à d’autres outils d’IA générative plus couramment utilisés, les navigateurs d’IA occupent une position au sein d’une infrastructure numérique, opérant dans une zone grise où les attentes en matière de protection de la vie privée, les garanties de sécurité et les normes industrielles n’ont pas encore été rattrapées.
Les navigateurs IA peuvent également agir de manière autonome, de sorte qu’ils peuvent involontairement exposer des données sensibles, mal interpréter vos intentions ou entreprendre des actions que vous n’aviez pas l’intention d’autoriser.
Avant de décider de faire confiance à un navigateur IA, il convient de comprendre ce qu’il fait réellement, quels sont les problèmes qui se posent encore aujourd’hui et quels sont les compromis que vous acceptez.
Cartographie de l’écosystème émergent des navigateurs d’IA
Atlas d’OpenAI et Comet de Perplexity représentent la première vague de navigateurs natifs de l’IA qui traitent le navigateur comme un agent actif plutôt que comme un outil de visualisation passif. Ils partagent une similitude technique : ils sont construits sur Chromium, le moteur open-source qui équipe Google Chrome.
C’est ce qui explique que l’ouverture d’un navigateur IA donne immédiatement une impression de familiarité. L’interface des onglets, le comportement de la barre d’adresse, les systèmes de signets et les outils de développement ressemblent beaucoup à Chrome car ils partagent l’architecture sous-jacente.
Google Chrome avec Gemini et Microsoft Edge avec Copilot ont ajouté des capacités d’IA en réponse à la sortie de ces navigateurs d’IA. Toutefois, il s’agit toujours de fonctionnalités superposées aux cadres traditionnels des navigateurs.
Les navigateurs natifs IA, tels que Dia, Comet ou Atlas, conçoivent chaque composant avec le traitement de l’IA au cœur. Le navigateur analyse en permanence le contenu, interprète vos objectifs et détermine comment vous aider avant que vous ne le demandiez. Si la fonction d’IA est supprimée, ils ne seront plus qu’une coquille vide.
Par ailleurs, les navigateurs améliorés par l’IA, tels que Gemini de Google dans Chrome ou Microsoft Edge avec Copilot, sont construits sur les architectures traditionnelles des navigateurs. Le navigateur sous-jacent fonctionne exactement comme il l’a toujours fait – l’IA fournit une assistance facultative lorsque vous l’activez.
Ces outils abordent tous le problème différemment, mais ils représentent la même évolution sous-jacente vers des navigateurs qui interprètent, résument et agissent activement en votre nom.
Notez que nous ne comparerons pas les listes de fonctionnalités dans les sections suivantes. Nous allons plutôt examiner le modèle architectural plus large, les risques qu’il introduit et ce que cette nouvelle classe de logiciels signifie pour les utilisateurs en général.
Qu’est-ce que les navigateurs IA ont de si particulier ?
Au cours des trente dernières années, les navigateurs web ont surtout été des outils de visualisation passifs. Bien qu’ils offrent des fonctionnalités telles que les gestionnaires de mots de passe et le remplissage automatique des formulaires, ils ne peuvent pas aider à effectuer des tâches complexes.
La “magie” de l’écosystème émergent du navigateur IA réside dans le fait qu’il passe d’un outil qui affiche le web à un agent actif qui le comprend – ce qui signifie qu’il peut réellement vous assister dans des tâches complexes.
Meilleur contrôle du navigateur grâce à des invites en langage naturel
Au lieu de fouiller dans les menus et de se souvenir de l’endroit où se trouve un paramètre spécifique, vous pouvez simplement dire à un navigateur IA ce que vous voulez faire. Il s’agit moins de cliquer sur des boutons que d’exprimer ses intentions, dans un langage clair et simple, à l’aide de la barre de commandes du navigateur.
Au lieu de faire défiler les pages pour trouver l’option “Imprimer au format PDF”, il vous suffit de taper “Enregistrer ce reçu dans mon dossier Finances”. Le navigateur comprend ce que vous voulez dire et effectue les actions – exactement comme vous demanderiez à un assistant personnel de faire quelque chose pour vous.
La fin du tab tetris
Les navigateurs intelligents réduisent la nécessité de passer constamment d’un onglet à l’autre.
Faire une recherche en ligne avec un navigateur classique peut entraîner une surcharge d’onglets. Vous ouvrez un onglet pour comparer les produits, un autre pour vérifier les détails et un autre pour rechercher des sujets connexes, puis vous passez de l’un à l’autre pour trouver ce dont vous avez besoin.
Au lieu de cliquer dans tous les sens ou de les répartir dans plusieurs fenêtres, les navigateurs intelligents peuvent synthétiser les informations des différents onglets en une seule vue. Il suffit que tous les onglets soient ouverts.
Par exemple, vous vérifiez les horaires de vol dans un onglet, vous recherchez des hôtels dans un autre et vous consultez votre calendrier dans un troisième. Dans le panneau d’invite latéral, vous pouvez demander à l’IA de créer une liste des meilleures options d’horaires de vacances avec le prix de vol le plus bas et l’heure de vol la plus pratique.
Un navigateur qui se souvient de vos préférences
Les navigateurs standard stockent par défaut des données telles que l’historique, les cookies et le remplissage automatique, mais ils ne comprennent pas vos objectifs, votre contexte ou vos tâches en cours.
Les navigateurs d’IA renversent cette idée. Ils gardent en mémoire les choses que vous parcourez.
Si vous passez un lundi à chercher des chaussures de randonnée, le navigateur note votre pointure, les marques que vous aimez et si vous avez besoin d’une imperméabilité. Lorsque vous revenez quelques jours plus tard, même sur un site web complètement différent, il utilise cette connaissance pour filtrer les résultats automatiquement.
Au lieu de repartir à zéro à chaque fois, le navigateur conserve votre contexte en vie. Il s’agit moins d’un outil de navigation que d’une extension de votre propre mémoire à long terme.
La synthèse plutôt que le résumé
Les navigateurs d’IA modifient également la manière dont nous traitons l’information – ils ne se contentent pas de résumer un long article, mais peuvent également rassembler des idées provenant de différentes sources.
Un navigateur IA peut regarder une vidéo YouTube et sauter à l’heure précise dont vous avez besoin, parcourir trois articles en désaccord les uns avec les autres et lire un fil de discussion Reddit, puis combiner le tout en une seule explication claire. Le navigateur cesse d’être une source d’informations et devient un filtre qui vous donne l’essentiel, en vous apportant directement la clarté.
Le passage de l’affichage d’informations à l’exécution d’actions
Les produits d’IA générative les plus connus, tels que ChatGPT, Claude ou Perplexity, sont construits à l’aide de grands modèles de langage (LLM). Ils peuvent expliquer, résumer, répondre et raisonner, mais ils ne peuvent effectuer aucune action. Lorsqu’un LLM vous aide à “réserver un hôtel”, il génère des instructions textuelles que vous devez encore exécuter.
Les navigateurs d’IA intègrent en outre de grands modèles d’action (LAM), ce qui leur permet de créer des actions. Un LAM peut observer une page web, comprendre sa structure (boutons, champs, menus, flux) et interagir avec elle en votre nom.
Au lieu de chercher un restaurant, de vérifier les disponibilités et de remplir le formulaire de réservation, vous pouvez simplement dire : “Réservez une table pour deux dans un restaurant gastronomique à 19 heures”. Le navigateur envoie alors un agent IA qui clique sur les boutons, remplit le formulaire et s’occupe de tout en coulisses.
Les navigateurs intelligents ne peuvent apporter de la commodité qu’en obtenant une visibilité sur ce que vous cliquez, ce que vous lisez et ce à quoi vous revenez. Tout comme la formation d’un nouvel assistant personnel que vous avez embauché, il peut bien faire son travail s’il dispose d’un contexte suffisant.
Pour s’assurer que les résultats générés correspondent bien à vos préférences, les navigateurs IA intègrent une couche de mémoire. Même si cette mémoire se trouve localement sur votre appareil, l’IA se souvient toujours des modèles de votre comportement, à moins que vous n’effaciez explicitement cette mémoire.
Cependant, comme indiqué sur la page Contrôle des données et confidentialité d’Atlas, l’effacement de la mémoire de votre navigateur signifie que toutes vos habitudes de navigation seront également effacées. Une fois que vous avez fait cela, c’est comme si vous licenciiez votre assistant personnel expérimenté et que vous deviez former quelqu’un de nouveau à partir de zéro.
Notez également que l’apurement de l’histoire ne signifie pas nécessairement l’apurement de la compréhension. Il est possible de supprimer les journaux tout en conservant les modèles de préférence, principalement si l’IA utilise des embeddings ou des bases de données vectorielles locales pour établir un profil de ce qui compte pour vous.
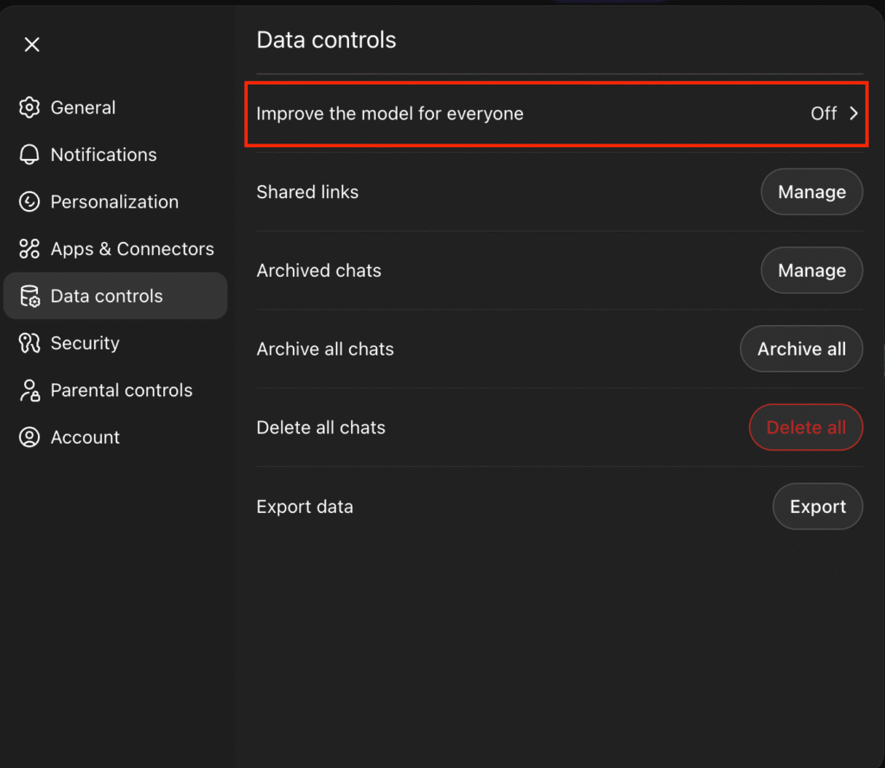
Comme indiqué sur la même page, Atlas vous permet de désactiver le paramètre “Améliorer le modèle pour tous”. Cela empêchera OpenAI d’utiliser vos données pour entraîner son modèle d’IA. Cela dit, si le même paramètre est activé dans votre application ChatGPT, votre navigateur Atlas suivra automatiquement. Si vous souhaitez désactiver cette fonction, allez dans votre ChatGPT Paramètres → Contrôle des données et désactivez-la.
Par ailleurs, chaque navigateur d’IA a sa propre façon de traiter les données. Perplexity’s Comet, par exemple, indique dans sa politique de confidentialité qu’elle peut utiliser certaines de vos informations pour améliorer ses services, y compris son modèle d’IA.

Même lorsqu’un navigateur IA vous permet de supprimer votre historique, de révoquer des autorisations ou de réinitialiser votre profil, il existe une limite inhérente à l’apprentissage automatique. Une fois qu’un modèle a été entraîné sur vos données, il ne peut pas être complètement désentravé.
Nous avons déjà observé une dynamique similaire avec les LLM grand public, qui sont en quelque sorte le moteur des navigateurs d’IA. Pensez aux premières images générées par l’IA en 2023 : les résultats étaient souvent déformés ou incohérents. En 2025, les résultats sont beaucoup plus proches d’une image réelle. Cela s’est produit parce que des millions d’utilisateurs ont fourni des données qui ont aidé les modèles à s’améliorer.
Un compromis plus profond et à plus long terme est d’ordre psychologique. Plus le navigateur anticipe ce que vous voulez, moins vous vous livrez aux petits actes quotidiens que sont le choix, la comparaison et la décision. Ce sont les micro-compétences qui constituent la pensée indépendante.
Au fil du temps, le fait d’avoir recours à des assistants pour résumer, hiérarchiser ou recommander peut vous faire passer de la direction de votre flux de travail au suivi de celui-ci. Il ne s’agit pas d’un résultat garanti, mais d’une conséquence réaliste de l’externalisation des efforts cognitifs.
Une expérience de navigation subtilement contrôlée
Les navigateurs conventionnels s’appuient sur des normes ouvertes vieilles de plusieurs décennies, créées par le World Wide Web Consortium (W3C) ou le Web Hypertext Application Technology Working Group (WHATWG). C’est pourquoi Chrome, Firefox, Safari et Edge peuvent tous accéder à n’importe quelle page web.
En plus de ces technologies standard, les navigateurs classiques utilisent un filtrage algorithmique pour classer les résultats de recherche, en affichant les liens et les extraits qui semblent les plus pertinents. L’utilisateur décide ensuite des sources à explorer, ce qui lui permet de garder le choix final entre ses mains.
Les navigateurs IA, en revanche, fonctionnent à la fois comme un navigateur, un moteur de recherche et un assistant, résumant, réécrivant ou omettant souvent complètement le contenu, sans que vous sachiez ce qui a été filtré ni pourquoi.
Pour le confort des utilisateurs, les navigateurs d’IA disposent d’une nouvelle couche au-dessus du rendu web standard qui est construite sur des écosystèmes d’IA propriétaires, et qui ne suit pas de règles communes :
- la façon dont ils interprètent les pages web
- la façon dont ils résument ou réécrivent le contenu
- comment ils agissent sur les sites web
- la manière dont ils stockent ou utilisent la mémoire des utilisateurs
- comment les agents interagissent avec les outils ou les API
Chaque navigateur IA exploite sa propre pile, combinant un navigateur, un moteur de recherche et un assistant IA en un seul produit. Cela signifie qu’une entreprise ne se contente pas de vous aider à naviguer sur le web, mais qu’elle façonne également ce que vous voyez, ce que vous ignorez et, en fin de compte, ce que vous choisissez.
L’algorithme devient votre gardien, et comme son raisonnement est privé, vous ne savez pas pourquoi il fait les choix qu’il fait.
Et ce n’est pas malveillant, c’est simplement la façon dont les systèmes de génération de réponses se comportent. Cela dit, il introduit un biais architectural, où les données d’entraînement et les préférences internes du modèle deviennent l’éditeur invisible de votre réalité.
Si l’IA estime qu’un élément n’est pas pertinent, elle le supprime silencieusement, créant ainsi un biais d’information qui n’est perceptible que si l’on vérifie intentionnellement deux fois l’information en question. Le web ouvert devient algorithmiquement filtré à travers une lentille privée.
L’affaire DeepSeek montre comment cela se passe dans le monde réel. Comme l’a rapporté The Guardian, le modèle IA minimisait ou déformait les réponses sur des sujets spécifiques. Pour ce faire, il est possible de mettre en place un algorithme qui génère une sortie particulière.
Avec les navigateurs intelligents, un scénario similaire se produira lorsque vous rechercherez des informations ou ferez des recherches sur un sujet spécifique.
Comment les navigateurs d’IA remodèlent l’accès à l’information
Vous savez sans doute que Google Chrome collecte également une grande quantité d’informations vous concernant. Comme l’a révélé Cyber Press, Google recueille plus de 20 types de données différents, notamment l’historique de votre navigation et de vos recherches, les détails de votre appareil, les diagnostics et même les entrées de votre carnet d’adresses.
Lorsque vous vous connectez et que vous activez la synchronisation, toutes vos activités sont liées à votre compte Google et diffusées dans les services de recherche, Gmail, Maps, YouTube, les annonces – tout ce qui fait partie de l’écosystème et pour lequel vous avez donné votre accord.
C’est logique si l’on considère le modèle économique de Google. Google gagne de l’argent grâce à la publicité, qui dépend de sa capacité à savoir qui vous êtes, ce que vous aimez et ce que vous faites en ligne. Comme le dit Proton, Chrome est essentiellement le moteur de collecte de données de ce système.
Pourtant, Chrome est devenu un acteur dominant du marché. Cela ne s’est pas fait par la contrainte, mais par une réelle commodité pour la base d’utilisateurs.
Les navigateurs d’IA suivent un schéma similaire en amplifiant encore la commodité. La différence est que les enjeux sont plus importants : ils exercent un contrôle beaucoup plus profond sur la manière dont nous interagissons avec le web et dont nous accédons à l’information.
Si un navigateur IA parvient à dominer le marché de la même manière, il ne se contentera pas d’influencer le chargement des pages ou l’affichage des publicités. Il contrôlera la manière dont les informations sont interprétées, résumées et exploitées, décidant ainsi de la signification du web pour des milliards d’utilisateurs.
À première vue, les navigateurs AI semblent collecter moins de données que Google Chrome. Et dans certains cas, c’est le cas. Nombre d’entre eux privilégient le stockage “local d’abord”, ce qui signifie que vos données restent sur votre appareil à moins que vous ne déclenchiez une fonction nécessitant le traitement des données sur leur serveur en cloud.
Mais le fait est que les fonctions d’IA ne peuvent pas fonctionner localement à pleine échelle.
Lorsque vous demandez à un navigateur IA de lire une page web, de la résumer, de l’analyser ou d’entreprendre une action, le flux de travail se présente comme suit :
- Le navigateur lit la page.
- Il envoie le texte ou les métadonnées pertinentes aux serveurs en cloud de l’entreprise.
- Le serveur le traite à l’aide de ses modèles d’intelligence artificielle.
- Le résumé ou le résultat est renvoyé à votre appareil.
Ainsi, même si vous vous désengagez de l’entraînement des modèles d’IA, vos données doivent tout de même être transférées dans leur cloud pour y être traitées. L’option de refus ne limite que la réutilisation de vos données, et non leur transmission.
Si vous demandez à un navigateur IA d’automatiser des tâches telles que l’envoi d’un courrier électronique à quelqu’un ou la planification d’une réunion, il doit avoir accès à votre Gmail, à votre agenda Google, à vos fichiers Drive et à vos contacts pour effectuer ces actions. C’est cette intégration profonde qui la rend pratique – et risquée.
En d’autres termes, laisser Google détenir vos données comme un bâtisseur de profil complet signifie que vous devez faire confiance à la sécurité de son infrastructure. En déléguant l’accès à vos données Google à l’écosystème d’une autre entreprise, vous doublez votre exposition au risque.
Pourquoi les navigateurs IA sont fondamentalement vulnérables
La différence architecturale entre les navigateurs conventionnels et les navigateurs d’intelligence artificielle n’est pas seulement une question de fonctionnalités, mais aussi d’hypothèses fondamentales en matière de sécurité.
Les navigateurs conventionnels construisent la sécurité autour d’un modèle centré sur le document. Chaque site web fonctionne dans son propre environnement d’exécution isolé, régi par la politique de la même origine, le sandboxing et les autorisations des utilisateurs.
Un compromis sur un domaine ne donne pas automatiquement accès aux données ou aux capacités d’un autre domaine. Même lorsque les attaquants établissent une persistance, leur portée reste généralement limitée à un site, un profil de navigateur ou un appareil spécifique.
Les navigateurs conventionnels dissimulent également des capacités sensibles derrière des actions explicites de l’utilisateur. L’accès à votre appareil photo, à votre localisation ou à vos informations de paiement nécessite un consentement délibéré, ce qui limite ce que les codes malveillants peuvent faire sans votre intervention.
Cette architecture impose des contraintes aux attaquants. L’exploitation des navigateurs conventionnels nécessite souvent l’enchaînement de plusieurs vulnérabilités ou le redéclenchement d’un comportement malveillant d’une session à l’autre. Elle n’élimine pas les risques, mais elle fragmente et contient les attaques de manière à en limiter la portée.
Les navigateurs d’IA fonctionnent différemment. Ils accumulent l’historique de l’utilisateur, ses préférences et ses interactions dans une mémoire persistante qui informe le comportement autonome à travers les sites et les sessions. Au lieu de traiter chaque page comme un document isolé, l’IA conserve le contexte de qui vous êtes, de ce que vous avez fait et de ce que vous êtes susceptible de faire ensuite.
Voici ce que cela signifie en pratique : si un pirate compromet le processus de prise de décision de l’IA – par le biais d’une injection rapide, de données d’entraînement empoisonnées ou d’une mémoire manipulée – il ne se contente pas d’exploiter un seul site. Ils influencent un agent qui agit en votre nom tout au long de votre navigation.
Ce passage de documents isolés à des agences persistantes et multi-domaines crée des surfaces d’attaque qui n’existaient pas auparavant.
Une surface d’attaque persistante grâce à la mémoire à long terme
Les navigateurs IA s’appuient sur une mémoire persistante pour stocker votre contexte de navigation, vos préférences et votre historique au fil des sessions. Cela peut transformer une brèche temporaire en une porte dérobée permanente.
Des chercheurs de LayerX ont récemment révélé une grave faille dans ChatGPT Atlas qui exploite précisément cette architecture. Ils ont démontré qu’un attaquant pouvait utiliser une attaque CSRF (Cross-Site Request Forgery) pour injecter silencieusement des instructions malveillantes directement dans la mémoire à long terme d’Atlas.
Comme cet “empoisonnement de la mémoire” persiste d’une session à l’autre, un lien d’apparence innocente ne se contente pas de vous hameçonner une seule fois : il implante un agent dormant dans votre navigateur. La prochaine fois que vous demanderez à votre IA de “résumer mes courriels” ou de “vérifier mon solde bancaire”, elle pourrait silencieusement exfiltrer des données ou exécuter des commandes d’élévation de privilèges injectées des jours ou des semaines auparavant.
En outre, dans de nombreux navigateurs IA, cette mémoire à long terme n’est pas limitée à un seul appareil. Pour assurer la continuité entre les appareils, le contexte de l’utilisateur et la mémoire à long terme sont souvent stockés ou synchronisés par l’intermédiaire d’un service centralisé.
Lorsque cette couche de mémoire est partagée entre plusieurs appareils, un compromis sur un appareil peut se propager à d’autres, élargissant ainsi la surface d’attaque au-delà d’une seule instance de navigateur. Ce qui commence comme un exploit localisé peut persister et refaire surface partout où l’assistant d’intelligence artificielle est actif.
Injection d’invites, attaques par fausse URL et code caché
Les navigateurs IA brouillent la frontière entre le contenu et les commandes en interprétant les entrées en langage naturel comme des instructions. Cela ouvre la porte à l’injection rapide indirecte.
Les enquêteurs en sécurité ont démontré l’existence du “HashJack” et d’autres attaques similaires, dans lesquelles une chaîne URL malveillante incite l’intelligence artificielle à exécuter des commandes cachées dans le fragment d’URL (la partie située après le “#”). Comme ces fragments sont souvent invisibles pour les filtres de sécurité côté serveur, le navigateur IA les lit comme des instructions d’utilisateur hautement prioritaires.
Ces invites peuvent être encodées subtilement dans un texte blanc sur fond blanc, cachées dans les métadonnées d’une image ou enfouies dans les commentaires d’une page. Les chercheurs comparent ce phénomène à une version moderne et incontrôlable du Cross-Site Scripting (XSS), où le “script” est un langage naturel exécuté avec la pleine capacité de l’utilisateur.
Le danger réside dans l’autonomie. Une étude récente de l’université Carnegie Mellon a montré que lorsque les LLM sont dotés d’un “modèle mental” des opérations du système, ils peuvent planifier et exécuter de manière autonome des cyberattaques complexes sans l’aide d’un guide humain. Ils peuvent simplement comprendre les étapes par eux-mêmes.
Fragmentation et incohérence des protections
La plus grande force du web est la normalisation. Des normes telles que HTML et TLS, régies par des organisations telles que le W3C, garantissent que les limites de sécurité sont universellement reconnues.
Les navigateurs d’IA, en revanche, sont construits sur des piles propriétaires et fragmentées. Chaque fournisseur définit sa propre logique de “sandboxing” et de mémoire.
Si de nouveaux protocoles, tels que le Model Context Protocol (MCP), apparaissent pour normaliser les connexions, ils donnent souvent la priorité à l’interopérabilité plutôt qu’à la sécurité, ce qui introduit de nouveaux risques, notamment des “flux d’agents toxiques”, où des données malveillantes provenant d’un outil s’infiltrent dans un autre.
Par conséquent, ce qui est considéré comme une mémoire “sûre” dans un agent peut être un vecteur d’injection ouvert dans un autre. En outre, les vulnérabilités sont essentiellement des “boîtes noires”, sans norme universelle sur la manière dont un agent doit assainir les entrées avant d’agir sur elles.
L’externalisation de l’agence vers des systèmes que nous ne pouvons pas inspecter
La magie des navigateurs IA est aussi leur plus grande vulnérabilité. Plus nous cédons le contrôle à des systèmes opaques, plus nous devenons des consommateurs passifs de décisions prises par des algorithmes que nous ne pouvons pas contrôler.
Une étude de 2025 sur les écosystèmes d’agents alimentés par le LLM souligne ce risque systémique. Elle a identifié plus de 30 techniques d’attaque potentielles distinctes, couvrant la manipulation des données d’entrée, la compromission des modèles et l’exploitation des protocoles. Il s’agit de défauts structurels découlant de la conception d’agents autonomes.
Tant que les normes ouvertes et les pare-feu “agentiques” rigoureux n’auront pas rattrapé leur retard, l’adoption d’un navigateur d’IA revient à troquer l’agence contre la commodité.
Problèmes non résolus et déficit de responsabilité
Actuellement, le risque lié à l’utilisation des navigateurs d’IA vous incombe entièrement. Les conditions d’utilisation de ces outils exonèrent souvent explicitement le vendeur de toute responsabilité pour les actions de l’agent.
Par exemple, les conditions d’utilisation du navigateur Comet de Perplexity se réservent le droit de mettre à jour les fonctionnalités ou de corriger le logiciel sans demander votre autorisation.

Ils précisent que l’utilisation de l’outil se fait à vos risques et périls.

Dans le même temps, Dane Stuckey, directeur de la sécurité informatique de l’OpenAI, a ouvertement reconnu que l’injection rapide restait un problème de sécurité non résolu pour lequel l’industrie n’avait pas encore de solution claire.
Des questions essentielles concernant l’infrastructure, les limites de sécurité et les normes ouvertes restent sans réponse. Jusqu’à ce que l’industrie adopte un protocole de sécurité universel pour la mémoire LLM, ces outils sont à l’état de développement “Wild West”.
Nous ne pouvons ignorer que les navigateurs IA représentent une innovation révolutionnaire en matière d’expérience utilisateur. La possibilité de résumer des sujets complexes et de naviguer sur le web en langage naturel constitue un progrès considérable en matière de convivialité.
Toutefois, en gardant à l’esprit tout ce que nous avons évoqué ci-dessus, si vous souhaitez les utiliser, veillez à protéger votre agence de manière agressive. Lisez toujours attentivement les conditions de confidentialité et les politiques de collecte de données du navigateur AI avant d’accepter quoi que ce soit.
La plupart des navigateurs d’IA demanderont des autorisations étendues pour lire le contenu de l’écran, saisir du texte et gérer les onglets, car les agents d’IA ont besoin d’avoir une visibilité sur votre activité de navigation pour fonctionner efficacement. C’est le prix de votre confort. Si vous refusez ces autorisations, l’outil perd une grande partie de son attrait.
C’est pourquoi nous recommandons de considérer les navigateurs d’IA comme des outils spécialisés, et non comme vos outils de travail quotidiens. Utilisez-les pour rechercher des informations publiques, résumer des nouvelles, trouver des recettes ou naviguer dans des parties du web non sensibles, en “lecture seule”, où les enjeux sont faibles.
Continuez à utiliser des navigateurs conventionnels pour les opérations bancaires, les portails de soins de santé, le courrier électronique de l’entreprise, les panneaux d’administration internes et tout site nécessitant une connexion sécurisée. Séparer physiquement votre “identité” de votre “agent”.
Abstenez-vous toujours d’utiliser des navigateurs IA à des fins professionnelles. Edigijus Navardauskas, responsable de la cybersécurité chez Hostinger, déconseille l’utilisation de ces outils dans les environnements professionnels en raison de la forte probabilité de fuite de données.
Ce navigateur est une technologie impressionnante, mais en l’absence de réglementations établies ou d’une préparation vérifiée des entreprises, nous fonctionnons essentiellement sur la base d’un engagement de “confiance” en ce qui concerne les flux de données. Ce n’est pas une base pour la sécurité des entreprises”, note-t-il.
Les employés peuvent coller par hasard des données internes sensibles telles que des documents financiers, des feuilles de calcul ou des informations confidentielles dans l’assistant, sans savoir que les données quittent le périmètre de sécurité. L’IA intégrée entraîne un dangereux “brouillage” de la frontière entre les flux de données internes et externes.
Tout le contenu des tutoriels de ce site est soumis aux
normes éditoriales et aux valeurs rigoureuses de Hostinger.

Chaimaa est une spécialiste du référencement et du marketing de contenu chez Hostinger. Elle est passionnée par le marketing digital et la technologie. Elle espère aider les gens à résoudre leurs problèmes et à réussir en ligne. Chaimaa est une cinéphile qui adore les chats et l’analyse des films.