Si vous hébergez vous-même n8n, vous vous êtes probablement posé la même question que moi : Combien de ressources serveur mes flux de travail n8n consomment-ils réellement ?
En effet, il est essentiel de disposer de suffisamment de ressources pour maintenir des performances optimales, mais vous ne voulez pas dépenser trop d’argent pour des ressources de serveur qui ne seront pas utilisées.
Les sources en ligne indiquent différents nombres de cœurs de processeur et de mémoire vive, comme un processeur à un seul cœur et 2 Go de mémoire vive. Mais cela soulève des questions pratiques :
- Ai-je vraiment besoin d’autant de ressources pour un simple flux de travail ?
- Si je déploie deux flux de travail, ai-je besoin d’un serveur deux fois plus puissant ?
- Dans quelle mesure l’utilisation des ressources de n8n est-elle prévisible dans des scénarios réels ?
Pour répondre à ces questions, j’ai effectué une série de tests en conditions réelles afin de mesurer l’utilisation du CPU, de la mémoire vive et du réseau des flux de travail n8n dans différentes conditions.
Résumé : points clés
Avant d’entrer dans les détails, voici les points clés à retenir de mon test :
- La consommation de ressources dépend du nœud. Les nœuds qui interagissent avec des sources externes, comme le nœud de requête HTTP, consomment davantage de ressources d’E/S réseau que les nœuds qui exécutent des tâches localement. Cependant, la mémoire vive est la ressource dominante dans presque tous les nœuds, qu’ils soient internes ou externes.
- La mise à l’échelle est quelque peu linéaire. L’exécution de plusieurs flux de travail identiques se traduit souvent par une mise à l’échelle à peu près linéaire. Une fois la variété des nœuds introduite, l’utilisation des ressources devient beaucoup moins prévisible.
- Les retards ne réduisent pas le pic d’utilisation. L’ajout d’un intervalle entre les exécutions de nœuds n’affecte pas le pic d’utilisation. Cependant, il vous permet d’étaler l’allocation des ressources dans le temps pour faire de la place à d’autres flux de travail.
- Exécution parallèle ou séquentielle des flux de travail. Il n’y a pas de différence définitive dans l’utilisation maximale du matériel entre l’exécution de flux de travail en parallèle et en séquentiel.
- Le mode file d’attente du n8n n’est pas une solution miracle. L’activation du mode file d’attente n8n double grosso modo l’utilisation de la RAM de base, même en cas d’inactivité. Elle ne réduit pas les pics d’utilisation pour les petites installations et n’a de sens qu’à plus grande échelle.
Méthodologie du benchmark n8n
Ce benchmark se concentre sur l’utilisation maximale du CPU, de la RAM et des E/S réseau du serveur hôte.
Il convient de noter qu’il existe d’autres critères de référence pour le n8n. Par exemple, l’article du blog n8n Scalability Benchmark examine comment la plateforme gère un grand nombre de demandes, en se concentrant sur des mesures telles que le taux d’échec et le temps de réponse.
Cependant, au lieu d’un benchmark synthétique contrôlé, je me suis concentré sur l’utilisation maximale des ressources dans le monde réel, dans le cadre de scénarios d’automatisation pratiques.
Conseil d’expert
Si vous ne savez pas quel plan VPS Hostinger correspond le mieux à vos besoins, commencez par KVM 2 – il fournit une base solide et peut être mis à niveau instantanément en un seul clic au fur et à mesure que vos besoins augmentent.

Examinons la méthodologie plus en détail, en commençant par comprendre l’environnement de test.
Environnement de test et outils pour le benchmark n8n
Voici la configuration que j’ai utilisée pour effectuer les tests de référence n8n :
- Serveur. Plan d’hébergement Hostinger KVM 2 VPS.
- Système d’exploitation. Linux Ubuntu 24.04 LTS.
- Outil. btop pour la surveillance, Docker pour l’exécution de n8n dans un conteneur.
J’ai choisi Hostinger KVM 2 parce qu’il offre beaucoup de ressources sans être trop cher. Avec deux cœurs vCPU, 8 Go de RAM et 100 Go de stockage SSD NVMe, il offre une grande marge de manœuvre si les tests l’exigent.
En ce qui concerne le système d’exploitation, j’ai choisi Ubuntu 24.04 LTS simplement parce qu’il est stable, facile à utiliser et populaire. Si vous utilisez une distribution plus minimale, il peut y avoir de légères différences de performances, mais cela ne devrait pas changer la donne.
J’ai déployé n8n sur Docker. C’est l’approche d’auto-hébergement recommandée, et avec le modèle VPS d’Hostinger, l’installation de n8n dans un conteneur ne prend que quelques clics. J’ai également configuré le mode file d’attente n8n en utilisant le modèle de Hostinger et ses paramètres préconfigurés par défaut.
Faut-il tenir compte de la surcharge Docker ? 🐳
Docker fonctionne de manière proche des performances natives puisqu’il partage le noyau hôte. En pratique, la surcharge est négligeable par rapport à l’exécution de n8n directement sur l’hôte.
Pour la surveillance, j’ai utilisé btop parce qu’il est simple et suffisant pour collecter des données pour ce benchmark. Il fournit également un graphique qui simplifie le processus de surveillance.
Scénarios de test du benchmark n8n et métriques suivies
Pour réaliser le benchmark, j’ai effectué chacun des tests suivants à un intervalle de 2 secondes pendant plusieurs minutes afin d’obtenir des données cohérentes. Pour certains scénarios, j’ai augmenté l’intervalle pour éviter les limites de taux de l’API.
Pour chaque test, j’ai suivi les valeurs maximales pour :
- Utilisation du CPU
- Consommation de la RAM
- Réseau E/S
Test 1 : benchmark au niveau des nœuds
Ce test a permis d’isoler des nœuds individuels pour y répondre :
- Quelle quantité de CPU, de RAM et de bande passante réseau un nœud consomme-t-il ?
- Les nœuds qui interagissent avec des services externes nécessitent-ils plus de ressources que ceux qui fonctionnent de manière indépendante au sein de n8n ?
- La consommation de ressources augmente-t-elle linéairement avec le nombre de nœuds ?
Important ! Par souci de simplicité, j’appellerai nœuds externes les nœuds qui nécessitent une interaction avec des services externes et nœuds internes ceux qui fonctionnent de manière indépendante au sein de n8n.
Test 2 : benchmark pour un workflow unique
Ce test porte sur des flux de travail complets :
- Flux de travail simple avec deux nœuds internes
- Flux de travail complexe avec sept nœuds internes
- Flux de travail complexe avec un total de sept nœuds, une combinaison de nœuds internes et externes.
- Effet de l’ajout de délais d’exécution
Test 3 : plusieurs workflows dans une seule instance
Ce test a examiné :
- La consommation de CPU, de RAM et de trafic augmente-t-elle de façon linéaire avec le nombre de flux de travail identiques ?
- La consommation de ressources est-elle prévisible en fonction du nombre et du type de flux de travail en cours ?
- L’exécution alternée de plusieurs flux de travail est-elle une stratégie viable pour minimiser les pics de ressources ?
Test 4 : Benchmark en mode file d’attente
Je voulais vérifier l’impact du mode queue de n8n sur la consommation de ressources d’un flux de travail :
- Le mode file d’attente n8n permet-il de minimiser l’utilisation du CPU, de la mémoire vive et du réseau ? Si oui, de combien ?
- Quels sont les inconvénients éventuels de l’utilisation du mode file d’attente du n8n ?
- Le mode file d’attente de n8n est-il une option viable pour l’exécution de flux de travail sur un système bas de gamme ?
Entre les tests, j’ai attendu que l’utilisation des ressources revienne à un niveau proche de la base de référence afin d’éviter des résultats biaisés.
Important ! Lors de mes tests, il est arrivé que l’utilisation de RAM au repos s’écarte considérablement de la base de référence initiale. Dans ce cas, j’ai normalisé la valeur pour m’assurer que le résultat est cohérent. J’ai soustrait la nouvelle base de référence de la première, puis j’ai ajouté la différence au résultat du benchmark RAM. Par exemple, si la ligne de base initiale est de 800 Mo et la nouvelle de 824 Mo, la différence est de -24. Cela signifie qu’une utilisation de 900 Mo de RAM sera normalisée à 876 Mo.
Limites et mises en garde concernant le benchmark
Ce benchmark vise à refléter l’utilisation réelle des flux de travail n8n, mais plusieurs facteurs influencent les résultats :
- Variation des nœuds. Il existe des centaines de nœuds n8n ayant des comportements différents, qui peuvent consommer les ressources différemment de ceux que j’ai testés.
- Environnement d’hébergement. L’environnement d’hébergement et la configuration que j’utilise pour déployer n8n sont relativement minimes. Les performances peuvent être plus ou moins élevées selon le type de serveur, le système d’exploitation ou la méthode de déploiement que vous utilisez.
- Logique de flux de travail. Les flux de travail dans ce benchmark sont simples et n’impliquent pas de logique complexe. Si vos flux de travail traitent de grandes quantités de données ou de fichiers, attendez-vous à une utilisation plus importante des ressources.
- Échelle de déploiement. J’utilise des flux de travail contenant moins de 10 nœuds pour effectuer le test. L’utilisation d’un plus grand nombre de nœuds augmente la consommation de ressources.
Cela dit, soyons clairs : ce test n’est pas une solution universelle qui détermine la configuration matérielle minimale requise pour votre flux de travail n8n.
Vos résultats varieront en fonction de votre utilisation et de votre configuration réelles. Au lieu d’utiliser le résultat du test comme norme, considérez-le comme un guide pour comprendre le comportement réel de n8n, ce qui vous aidera à mieux planifier votre environnement d’hébergement et votre stratégie de mise à l’échelle.
Résultats du benchmark n8n
Voici le résultat de mon benchmark n8n avec différents scénarios de test.
Benchmark n8n au niveau des nœuds
Avant d’exécuter un nœud, j’ai vérifié la consommation de ressources du serveur au repos pour établir une base de référence.
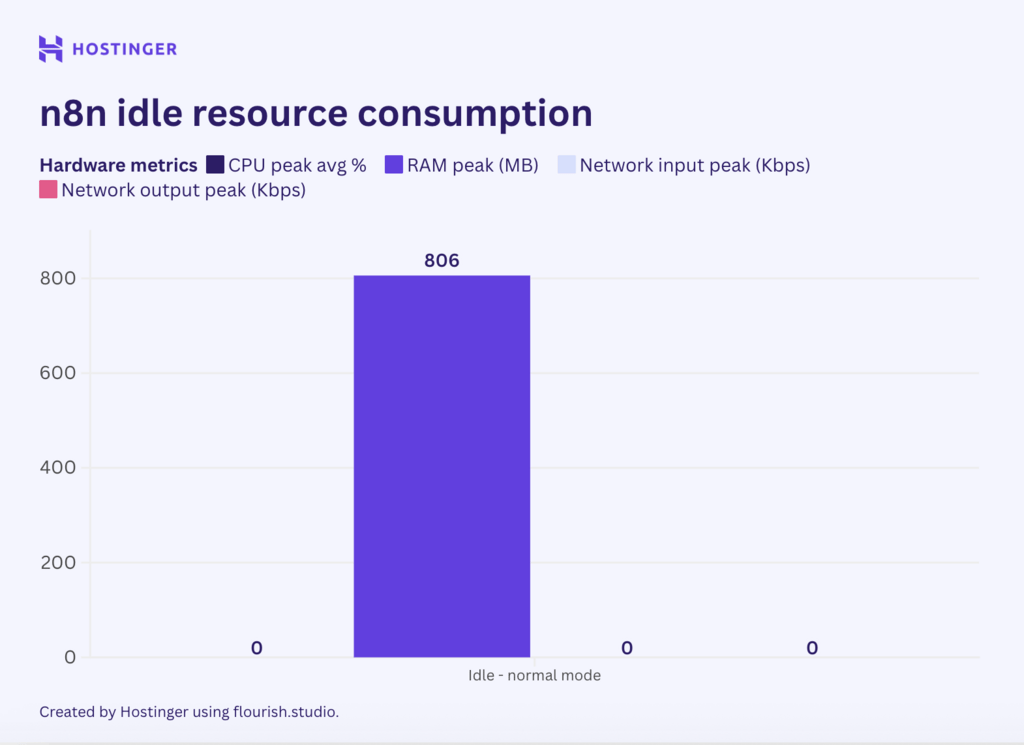
Sans nœud actif ni flux de travail, n8n a consommé 0 % du CPU et 860 Mo de RAM. L’E/S réseau n’a atteint que quelques octets ou un kilo-octet à un chiffre, c’est pourquoi je l’ai normalisé à zéro parce qu’il est insignifiant.
J’ai ensuite effectué le test avec ces flux de travail :
- Un flux de travail avec un seul nœud interne Code qui génère 1 00 nombres décimaux aléatoires à l’aide de JavaScript.
- Un flux de travail avec deux nœuds internes Code identiques, générant tous deux des nombres aléatoires de 100 décimales.
- Un flux de travail avec un seul nœud Google Sheet Get Row qui récupère les données d’une colonne d’une feuille.
- Un flux de travail avec deux nœuds Google Sheet, l’un pour extraire les données et l’autre pour les écrire.
La consommation de ressources pour tous les tests, par rapport à l’état d’inactivité, est la suivante :
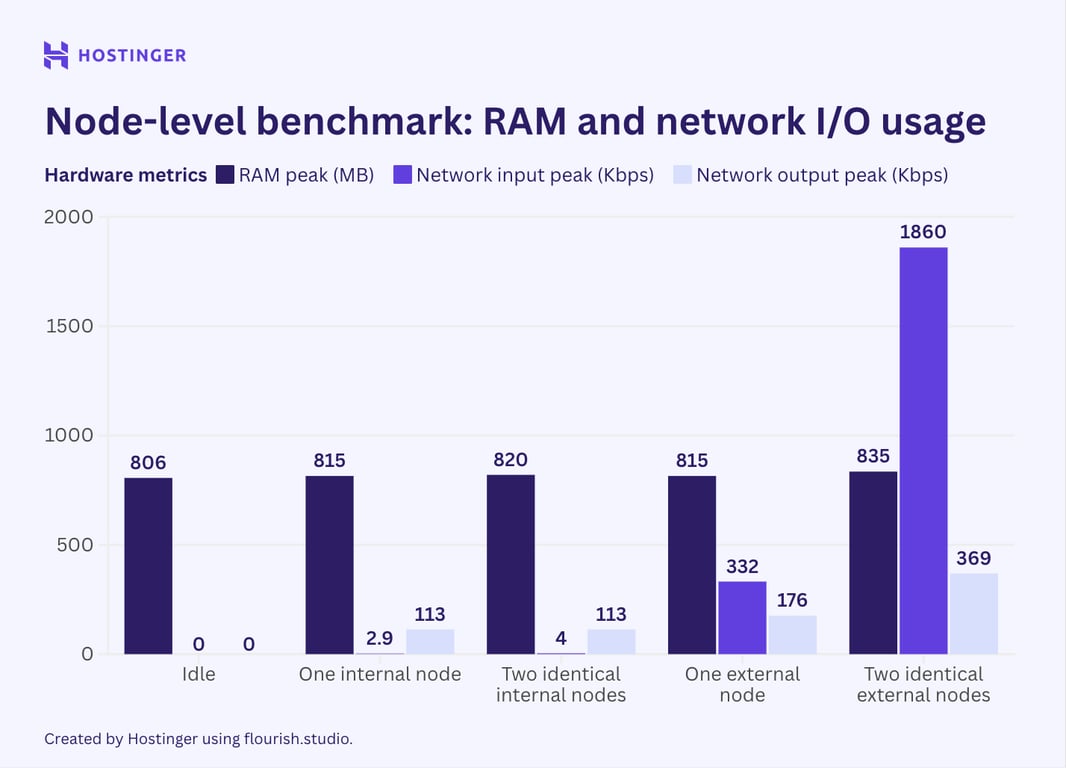
Les résultats sont conformes aux attentes : la consommation de ressources a augmenté lorsque j’ai ajouté des nœuds. Cela dit, le comportement de mise à l’échelle n’était ni linéaire ni prévisible.
Par exemple, un nœud interne a augmenté l’utilisation de la mémoire vive de 9 Mo par rapport à l’état d’inactivité. Cependant, lorsque j’ai inséré le même nœud, l’utilisation de la mémoire a augmenté de 5 Mo. Ce comportement était également présent avec les nœuds externes.
En ce qui concerne les nœuds externes, ils représentent en effet une charge d’E/S réseau plus importante, jusqu’à 10 fois supérieure à celle des nœuds internes. L’utilisation du réseau a également augmenté de manière significative lorsque j’ai ajouté le deuxième nœud externe, contrairement au CPU et à la RAM.
Benchmark n8n pour un workflow unique
Après avoir compris le comportement du nœud de manière isolée, j’ai voulu vérifier les performances d’un flux de travail réel. Voici une liste des flux de travail que j’ai utilisés :
- Flux de travail simple avec deux nœuds internes uniques pour générer 100 nombres entiers aléatoires et calculer la moyenne.
- Flux de travail complexe avec sept nœuds internes uniques pour générer des données aléatoires et exécuter diverses opérations telles que la normalisation.
- Flux de travail simple avec deux nœuds externes uniques qui récupèrent les données d’un Google sheet et les écrivent dans un autre document.
- Flux de travail complexe avec sept nœuds internes et externes uniques, avec pour tâche de récupérer les données VPS via l’API, de les filtrer sur la base de règles et de les enregistrer sur un Google sheet lorsque les critères sont remplis.
Voici les résultats pour tous les scénarios de test ci-dessus :
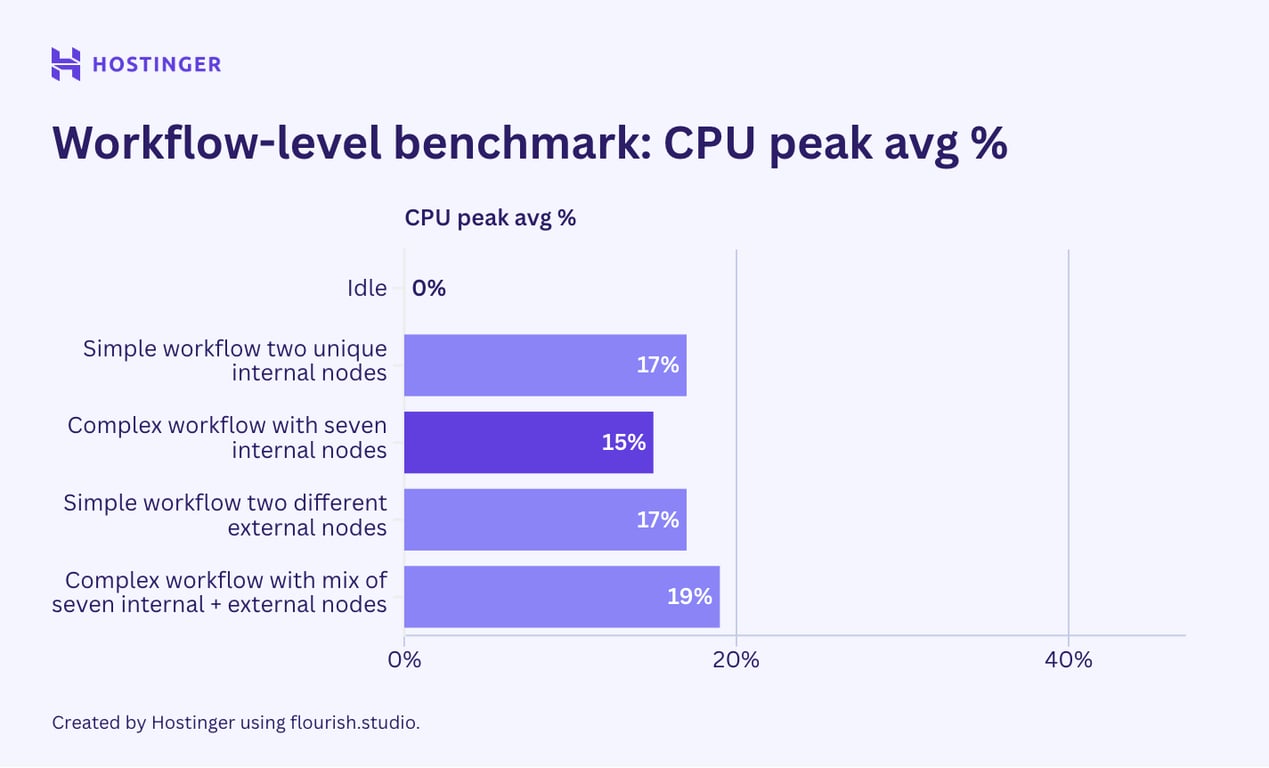
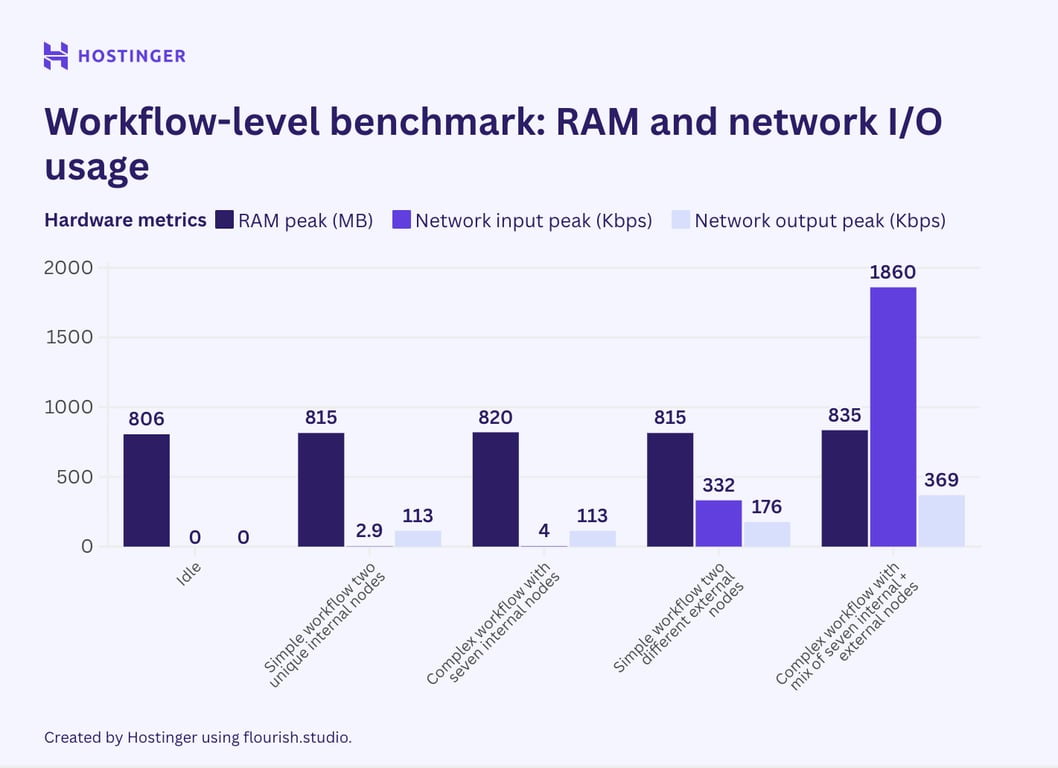
Les résultats montrent que l’ajout d’un nouveau nœud unique augmente davantage la consommation de ressources que l’insertion d’un nœud identique. Ce phénomène se retrouve à la fois dans les flux de travail simples et complexes, ce qui suggère que l’utilisation des ressources d’un flux de travail dépend de la variété de ses nœuds.
Le comportement de consommation des ressources dans ce second test semble également cohérent avec notre test au niveau des nœuds : les nœuds externes affectent de manière significative l’utilisation des E/S du réseau, alors que les nœuds internes ne le font pas.
Ensuite, j’ai ajouté un délai de 2 secondes à l’aide du nœud Wait dans les flux de travail complexes pour voir si l’arrêt de l’exécution réduit la consommation de ressources.
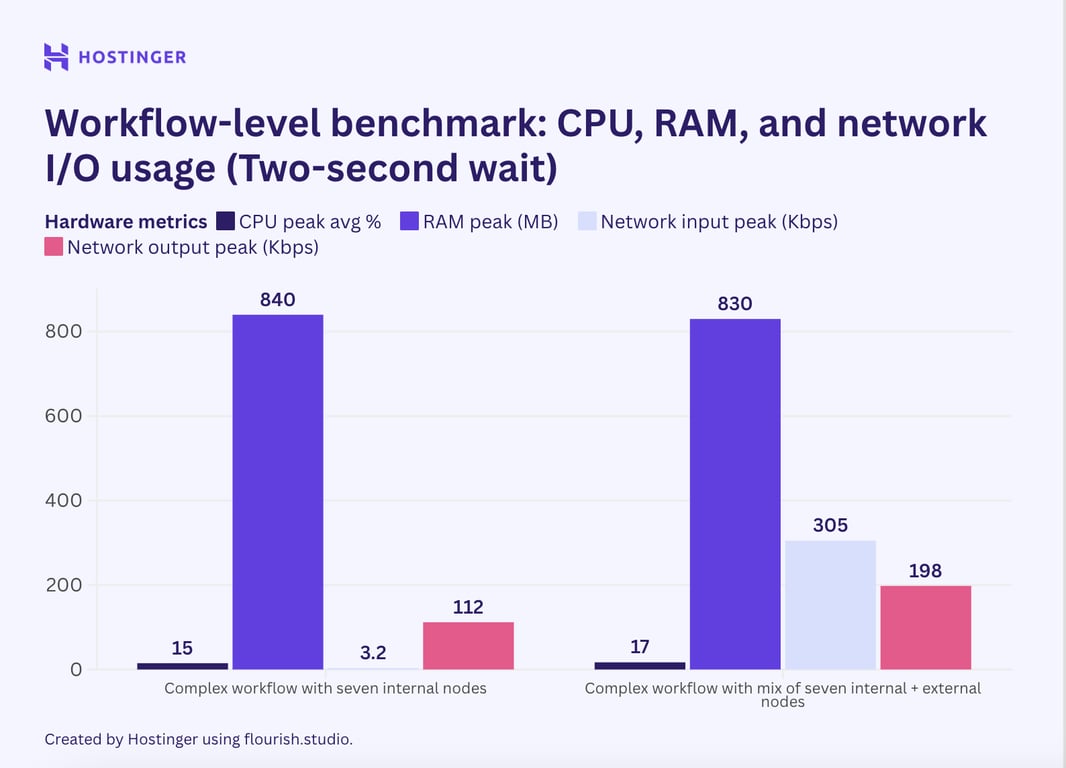
L’utilisation en période de pointe a légèrement diminué, mais on peut dire que la différence est insignifiante. Cela dit, l’intervalle permet de libérer des ressources à un moment précis, comme le montre ce graphique.
Benchmark n8n pour plusieurs workflows
Dans ce test, j’ai exécuté plusieurs instances des quatre mêmes flux de travail utilisés dans la section précédente. Voici le scénario :
- Exécution en parallèle de deux instances du même flux de travail. J’ai ajouté une instance supplémentaire si les ressources et la limite de débit de l’API le permettaient.
- Alternance de l’exécution de flux de travail identiques par l’intermédiaire de l’exécution des sous-nœuds. En d’autres termes, une fois le premier flux de travail terminé, la deuxième instance s’exécute.
- Exécution de différents flux de travail en parallèle. J’ai fait fonctionner un flux de travail interne simple en même temps qu’un flux de travail complexe.
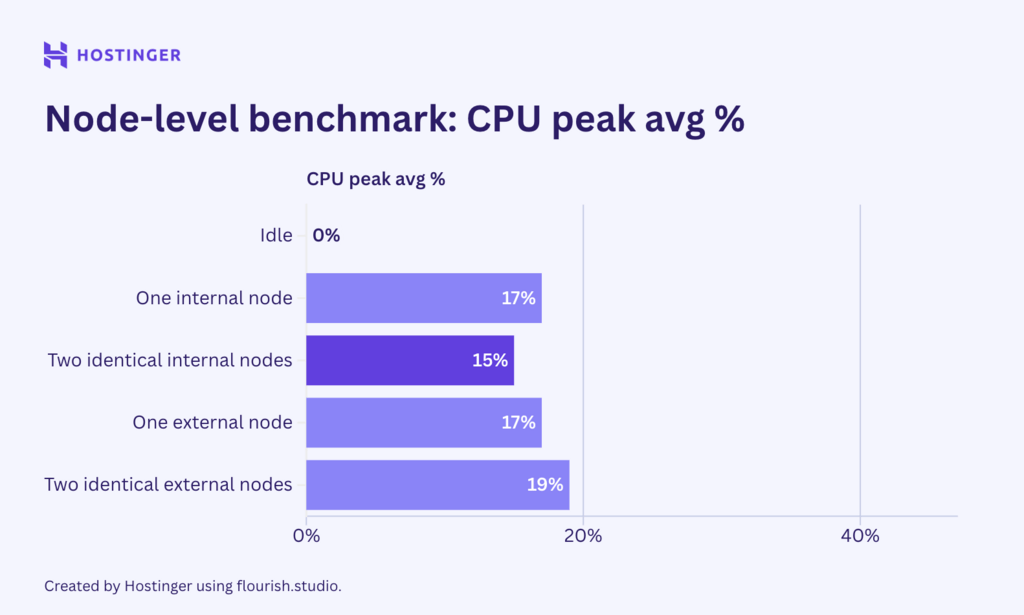
Commençons par vérifier les résultats du test du premier scénario, en nous concentrant sur les flux de travail simples avec deux nœuds :
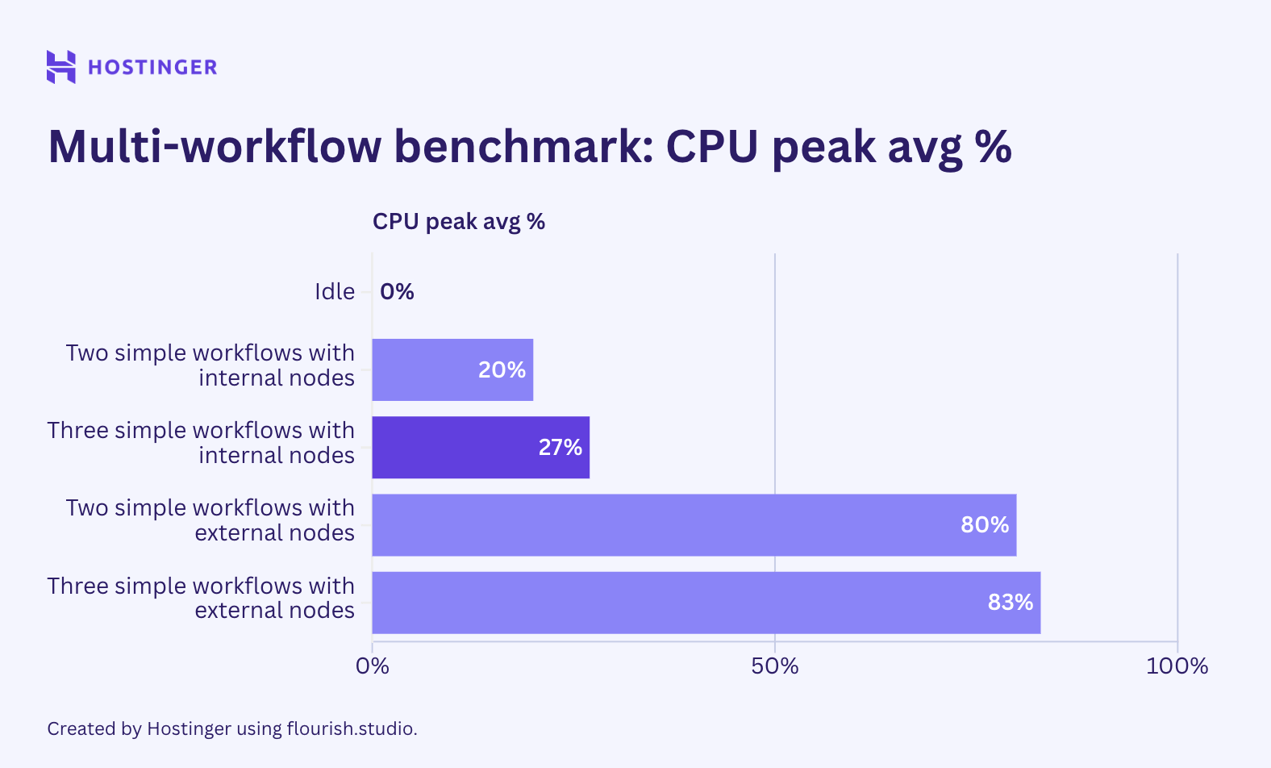
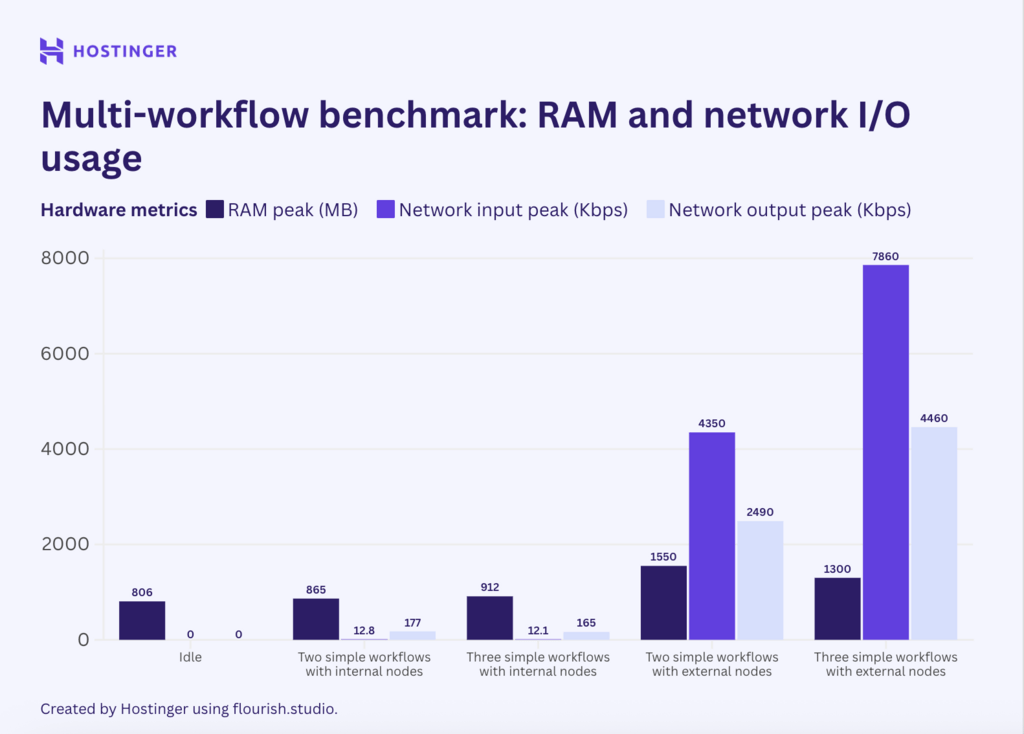
Un cas intéressant s’est produit. Pour les flux de travail simples avec des nœuds internes, l’utilisation des ressources était assez prévisible :
- Une exécution culmine à 17 % de la charge du CPU et à 815 Mo de RAM.
- Deux exécutions atteignent un pic à 20 % de la charge du CPU et 865 Mo de RAM.
- Trois exécutions atteignent un pic de 27 % de la charge du CPU et 912 Mo de RAM.
D’après la répartition, une exécution supplémentaire du flux de travail ajoute environ 40 à 50 Mo de RAM, et l’utilisation du CPU augmente de façon quelque peu linéaire.
En revanche, les flux de travail simples avec des nœuds externes présentaient une utilisation et un comportement de mise à l’échelle imprévisibles. La différence d’utilisation des ressources lors de l’exécution d’une, de deux et de trois instances est aléatoire, même si elle présente une tendance à la hausse.
Voyons maintenant comment se sont comportés les flux de travail complexes comportant sept nœuds :
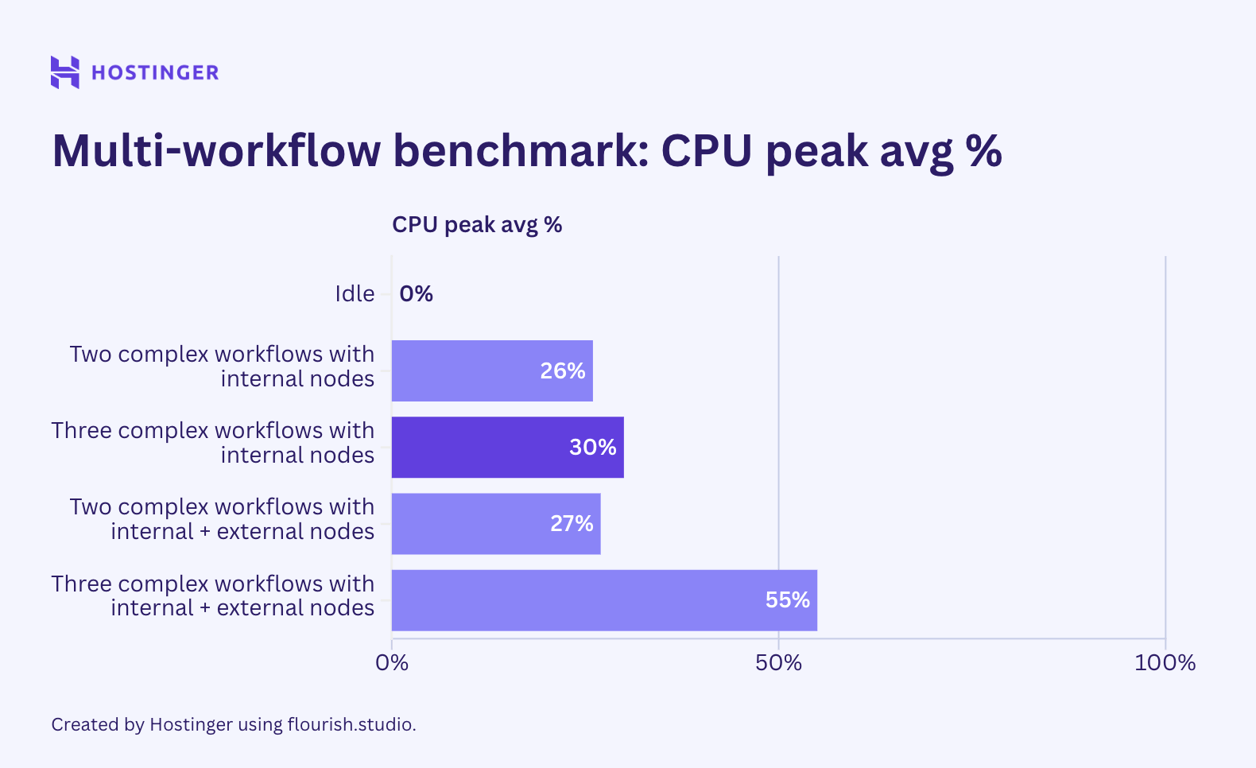
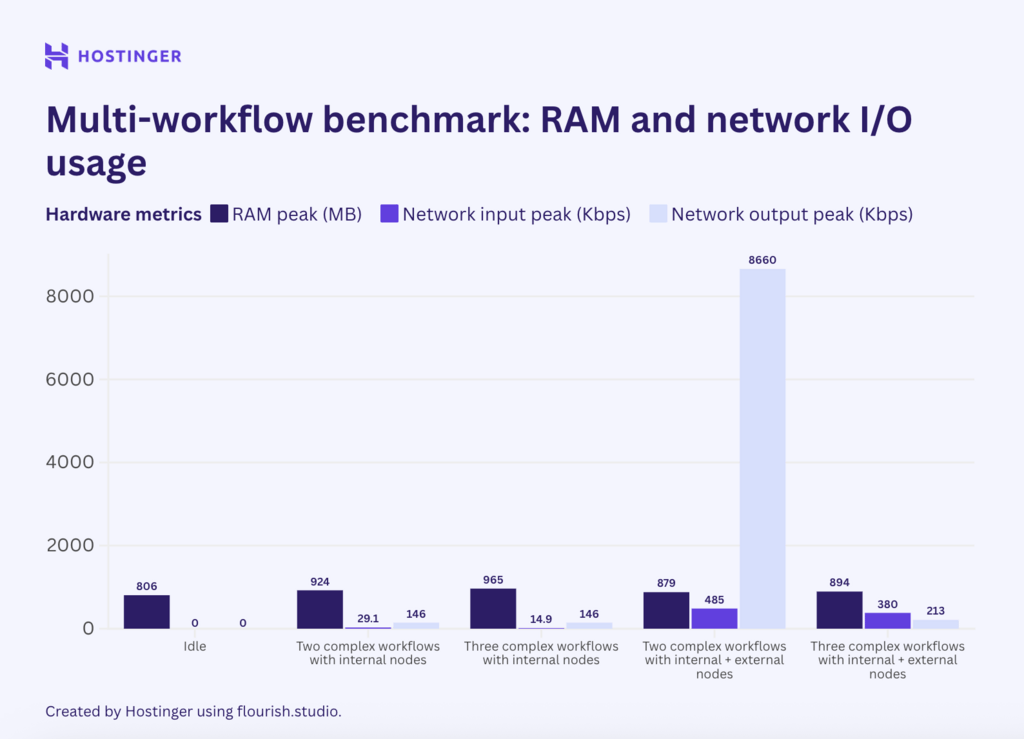
Le comportement du flux de travail simple était cohérent. L’utilisation des flux de travail avec des nœuds internes était relativement linéaire et prévisible. Par ailleurs, les flux de travail comportant un mélange de nœuds internes et externes présentaient une utilisation fluctuante, même dans les E/S du réseau.
Pour le deuxième scénario, j’ai enchaîné deux workflows identiques en utilisant le nœud d’exécution du sous-flow. Cela m’a permis de les exécuter dans un ordre différent. Le résultat est le suivant :
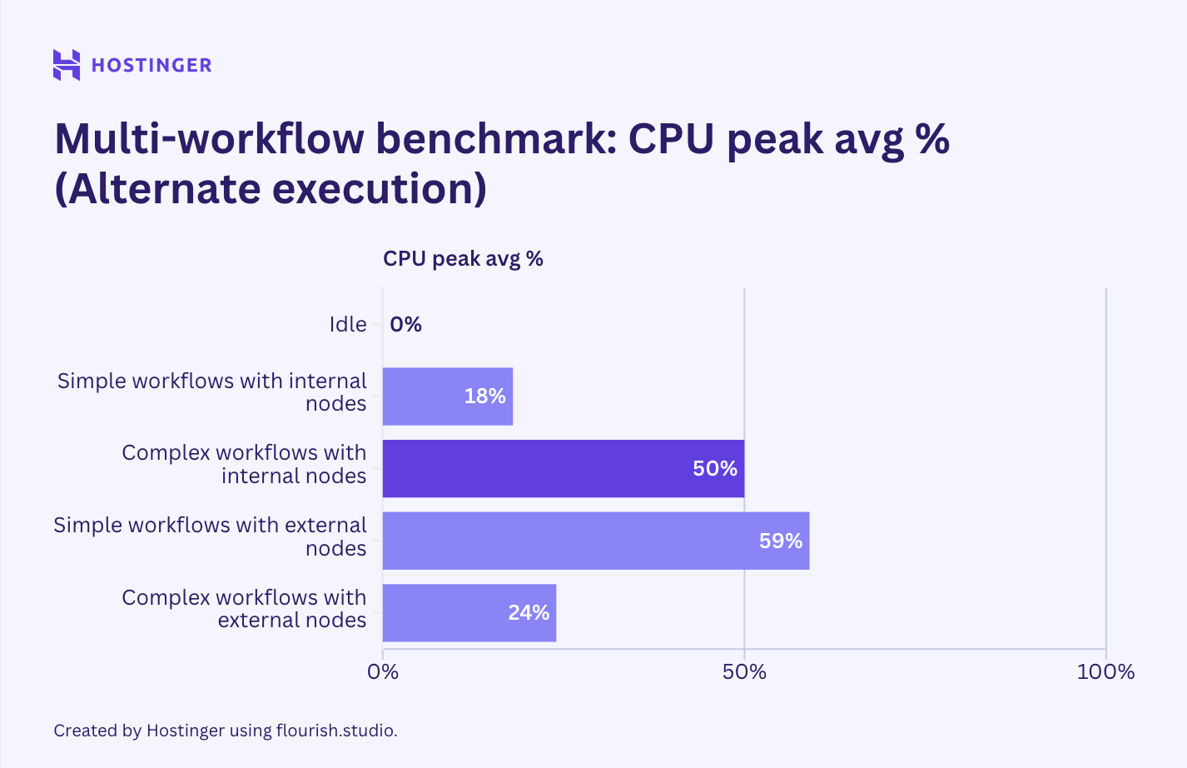
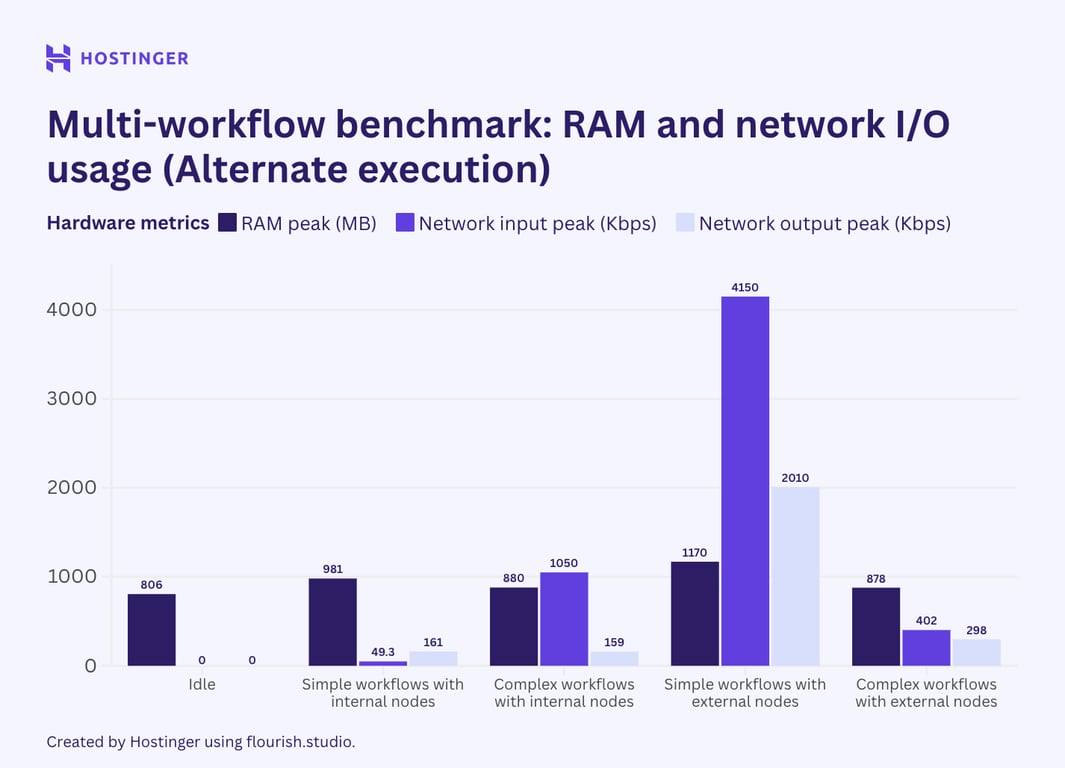
Comme on peut le voir, l’utilisation est restée relativement inchangée. Cependant, l’utilisation du CPU pour les flux de travail internes complexes a presque doublé lorsqu’ils sont exécutés dans un ordre linéaire par rapport à leur exécution en parallèle.
De même, la sortie réseau des flux de travail externes, lorsqu’ils sont exécutés dans un ordre linéaire, montre une baisse significative par rapport à leur exécution en parallèle.
Que nous apprennent les résultats ? 💬
À part les deux cas mentionnés, l’utilisation du matériel pour des workflows exécutés en parallèle ou de manière linéaire n’est pas très différente. La moindre sortie réseau lors de l’exécution alternative pourrait être due au dépassement du quota d’API, ce qui limite les échanges de données. L’entrée réseau plus faible, bien que moins marquée, indique également un problème de quota. Je n’ai pas d’explication plausible pour le pic de près de 100 % d’utilisation CPU lors de l’exécution alternative. Étant donné que tous les autres tests montrent que l’utilisation CPU reste identique ou légèrement inférieure pour des workflows exécutés de manière linéaire, cela pourrait être une anomalie.
Ensuite, j’ai testé le troisième scénario en exécutant un flux de travail interne simple en parallèle avec un flux de travail interne complexe.
Comme nous l’avons vu précédemment, un simple flux de travail interne a consommé environ 50 Mo de RAM et 7 % de l’utilisation du CPU. En comparaison, un flux de travail interne complexe a augmenté l’utilisation CPU d’environ 4 % et a nécessité 40 Mo de RAM supplémentaires.
Si l’utilisation de n8n est linéaire, l’exécution de ces flux de travail en parallèle augmenterait l’utilisation du CPU d’environ 11 % et utiliserait 90 Mo de RAM supplémentaires. Or, ce n’est pas le cas, comme le montrent les résultats de mes tests :
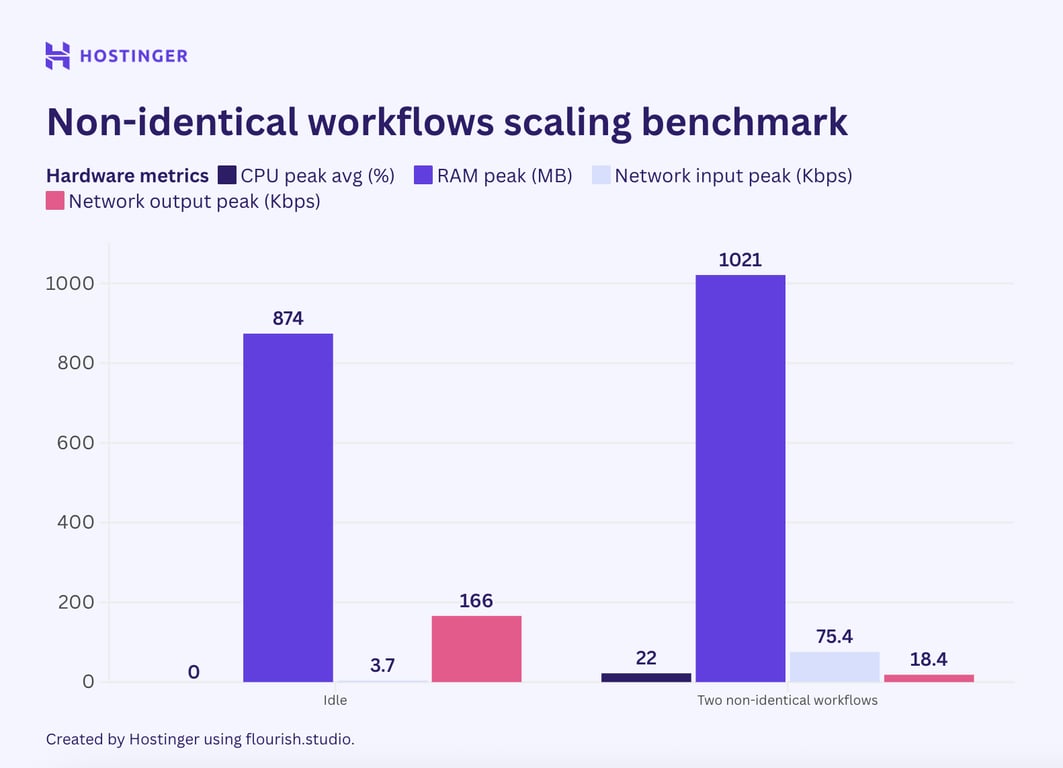
Sur la base de ces données, je doute que nous puissions prédire l’utilisation maximale des ressources de plusieurs flux de travail différents. Pour des flux de travail identiques, il est toujours possible de prédire l’utilisation du matériel, à condition que le nœud ne varie pas de manière significative.
Benchmark n8n avec mode queue
Le mode file d’attente n8n répartit vos tâches d’automatisation entre plusieurs travailleurs. Cela permet à chaque processus de fonctionner indépendamment de l’instance principale de n8n, ce qui contribue à décharger les tâches et à améliorer l’évolutivité.
Théoriquement, le mode file d’attente devrait améliorer la stabilité de votre automatisation lors de l’exécution d’un grand nombre de flux de travail. Dans cette optique, j’ai voulu réexécuter les flux de travail précédents en mode file d’attente pour voir si l’utilisation des ressources différait. Les scénarios de test sont les suivants :
- Exécution d’un flux de travail simple avec deux nœuds internes uniques. Ensuite, j’ai lancé une nouvelle instance du même flux de travail en parallèle, jusqu’à trois exécutions simultanées.
- Exécution d’un flux de travail simple avec deux nœuds externes uniques, ajout d’une nouvelle instance du même flux de travail exécuté en parallèle, jusqu’à trois exécutions simultanées.
- Déploiement d’un flux de travail complexe avec sept nœuds internes. J’ai ajouté une nouvelle instance du même flux de travail fonctionnant en parallèle, jusqu’à trois exécutions simultanées.
- Exécution d’un flux de travail simple avec sept nœuds internes et externes. Comme dans les scénarios précédents, j’ai ajouté une nouvelle instance du même flux de travail en parallèle, jusqu’à trois exécutions simultanées.
De manière surprenante, mon test a montré que l’utilisation de base de la RAM était deux fois supérieure au niveau normal du n8n, alors que le CPU et les E/S réseau restaient inchangés. Cela pourrait être dû à la création des travailleurs par n8n.
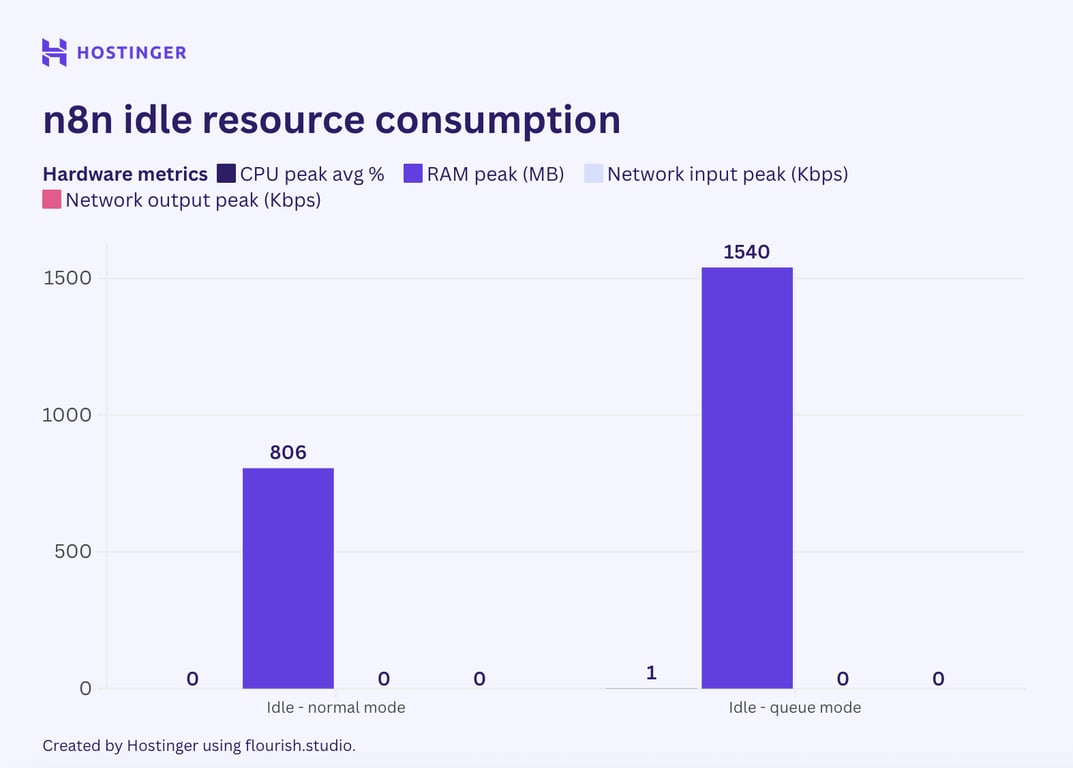
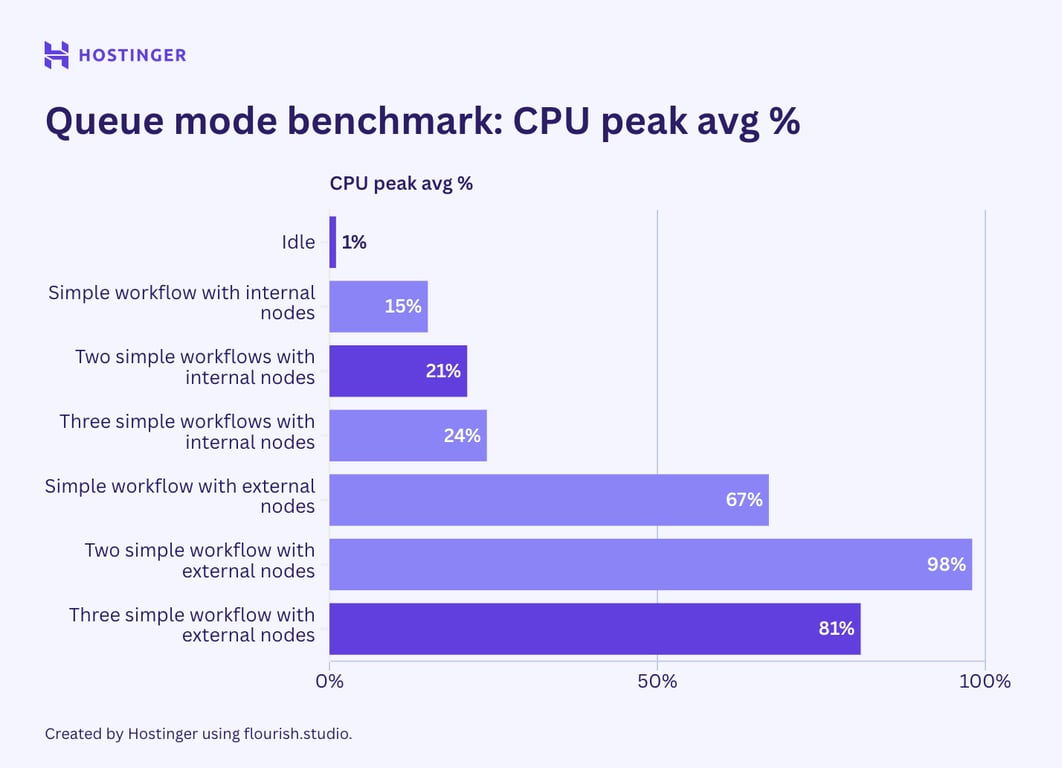
Examinons maintenant l’utilisation des ressources des flux de travail simples avec deux nœuds fonctionnant en mode file d’attente n8n.
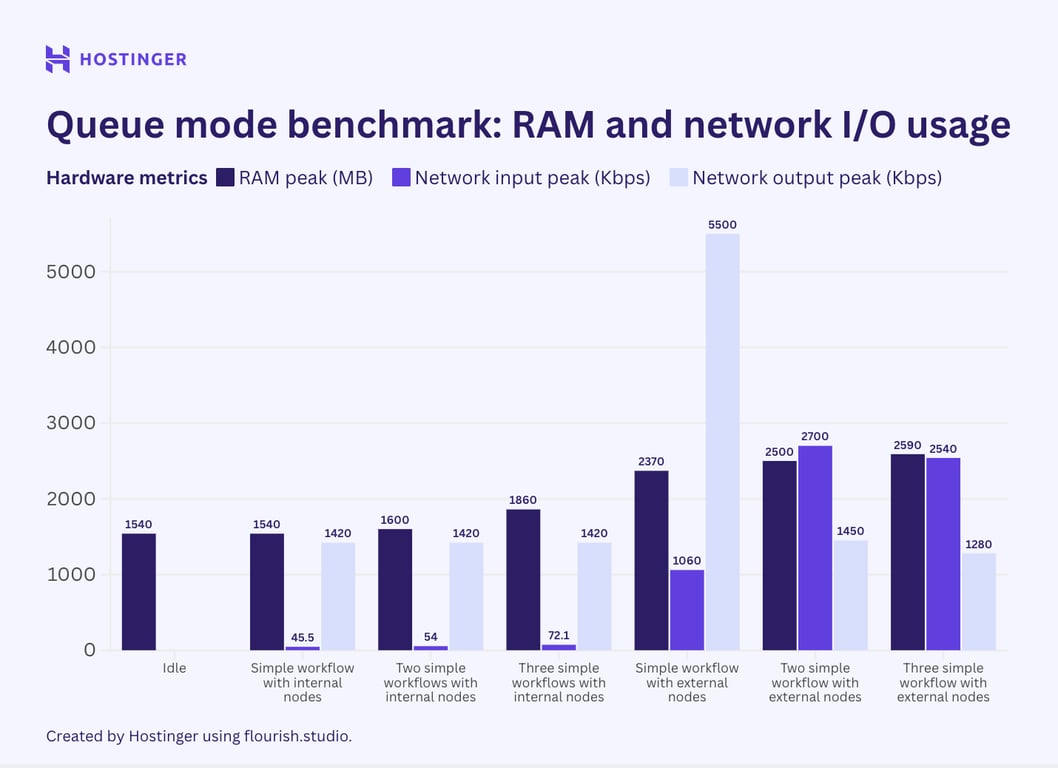
Il s’agit de l’utilisation du matériel pour des flux de travail complexes avec sept nœuds en mode file d’attente :
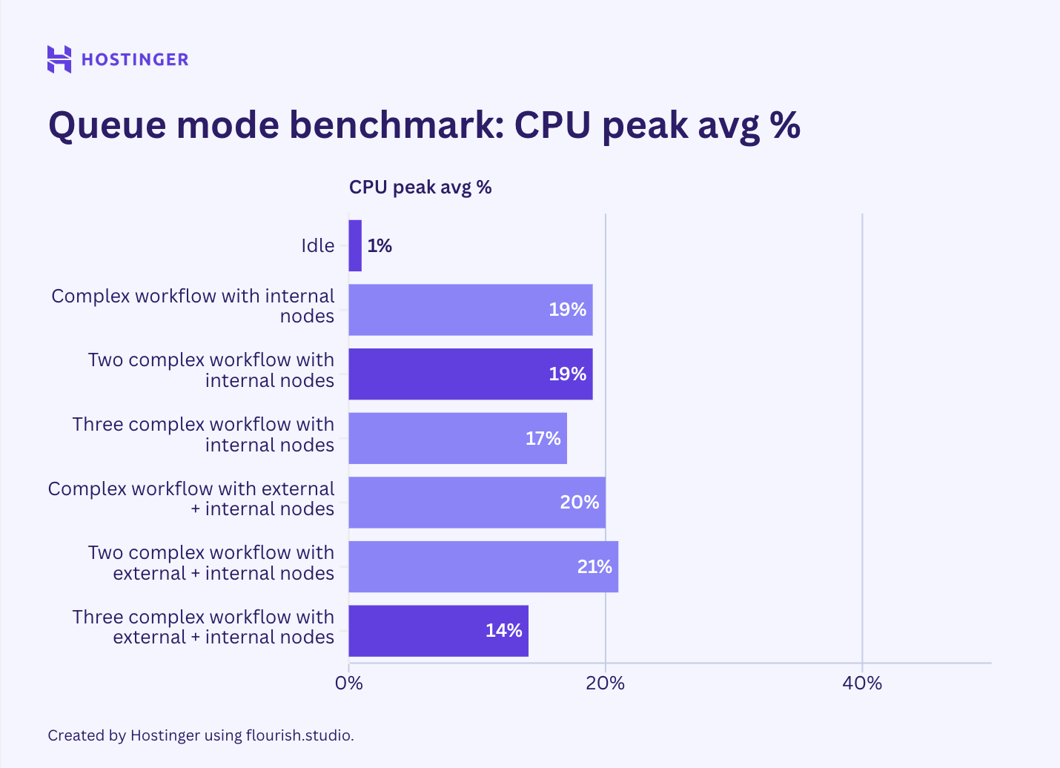
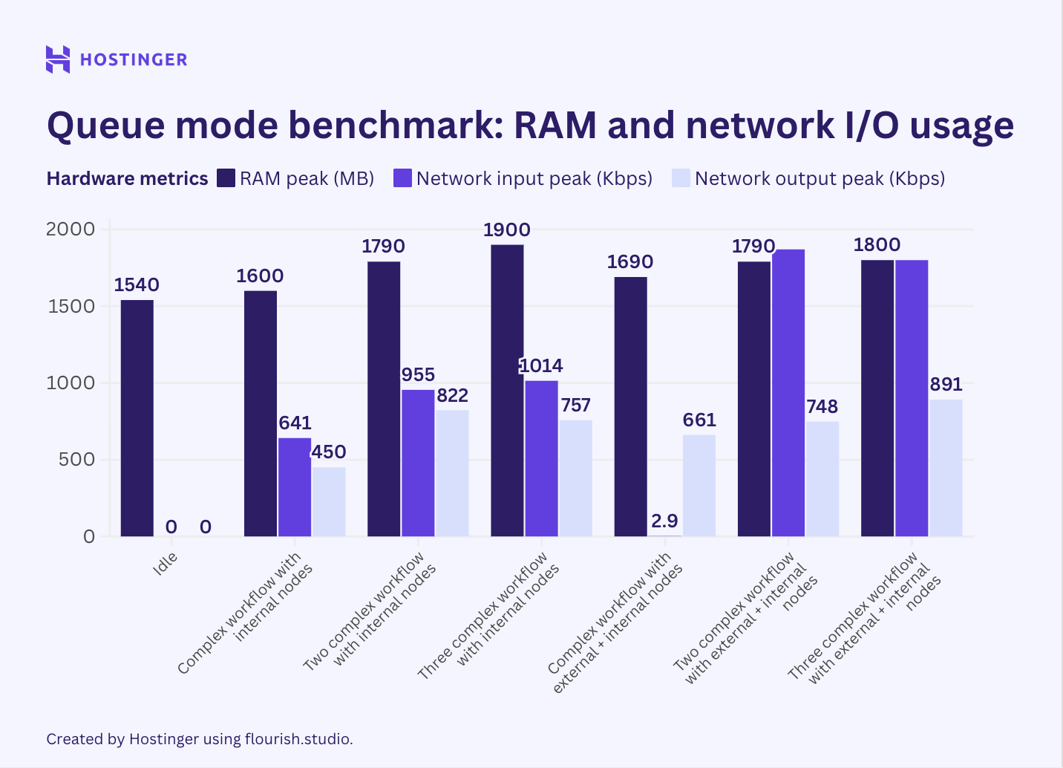
Contrairement à ce que je pensais initialement, les résultats du test indiquent que le mode file d’attente n8n ne contribue pas à réduire l’utilisation maximale des ressources. Bien que mon observation suggère que l’utilisation matérielle du mode file d’attente est plus stable que celle du n8n standard, la consommation moyenne est plus élevée.
Important ! Comme j’ai configuré le mode file d’attente n8n à l’aide du modèle VPS d’Hostinger, le nombre de workers a été fixé à trois par défaut. Notez que le nombre de workers aura un impact sur la consommation de ressources et l’exécution de votre flux de travail.
Lorsque j’ai ajouté davantage d’exécutions de flux de travail, je m’attendais à ce que l’effet du mode file d’attente soit plus apparent, mais ce n’était pas le cas. Par exemple, comparons le comportement de plusieurs exécutions d’un flux de travail complexe comportant sept nœuds internes en mode file d’attente et en mode vanilla :
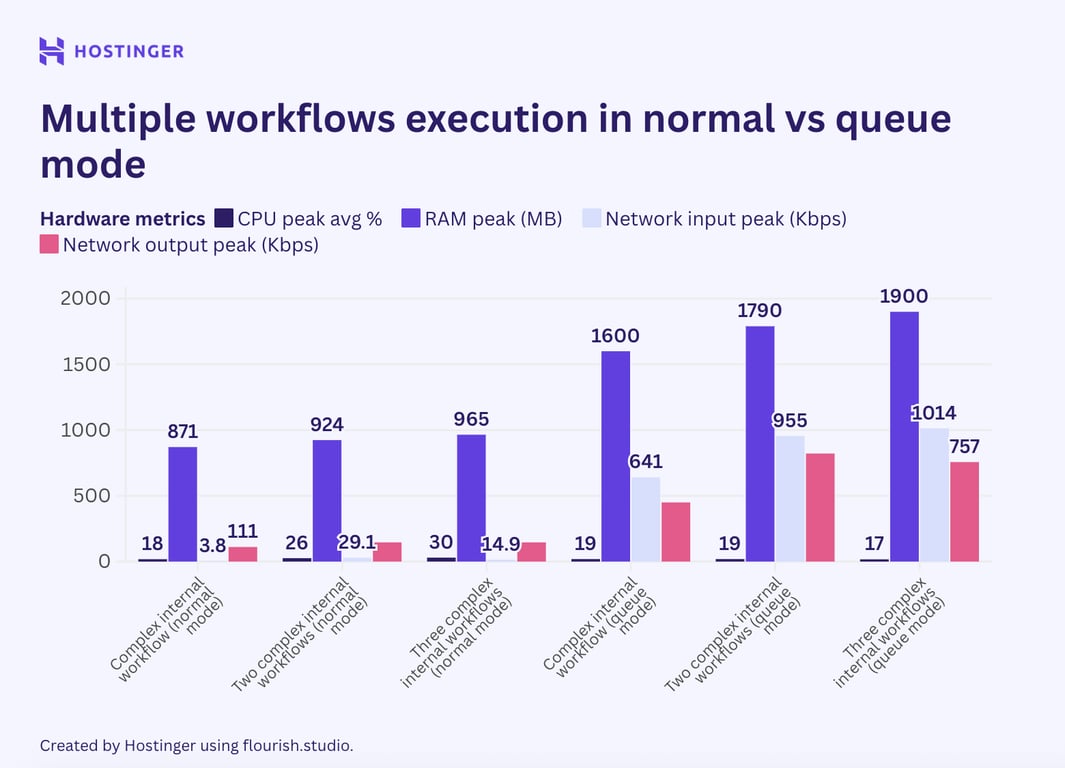
Dans le n8n vanilla, une exécution supplémentaire d’un tel flux de travail utilisait environ 40 à 50 Mo de RAM, alors qu’en mode queue, elle ajoutait au moins 60 Mo. Lors de l’exécution de trois instances de ce flux de travail, la consommation de mémoire vive a augmenté de plus de 100 Mo.
D’après le benchmark, nous comprenons que le mode queue du n8n n’est pas une solution qui peut magiquement vous permettre d’exécuter une charge de travail intensive sur une machine bas de gamme. En fait, ce mode consomme en moyenne plus de matériel que le mode normal.
Toutefois, si vous déployez des centaines de flux de travail, l’effet du mode file d’attente peut être plus évident. Elle est généralement recommandée lorsque votre configuration d’automatisation rencontre des problèmes tels que des webhooks qui traînent et une latence importante, où les charges de travail distribuées peuvent aider à maintenir la simultanéité.
Que nous apprend le benchmark n8n ?
Ce test a été conçu pour fournir une estimation approximative de la façon dont les flux de travail n8n utilisent les ressources. Étant donné que l’échantillon de données de test est petit, le comportement d’utilisation des ressources peut changer à l’échelle ou lorsque d’autres variables sont impliquées.
En outre, je me suis concentré uniquement sur les pics d’utilisation de la RAM, du CPU et des entrées/sorties réseau. Si vous considérez plutôt des moyennes et d’autres mesures, telles que le temps d’exécution du flux de travail, le comportement de n8n peut être différent.
Recommandation pratique
Si vous commencez avec 10 à 20 flux de travail, je vous recommande de les héberger sur un serveur disposant d’au moins 4 Go de RAM. Même si vous prévoyez que votre automatisation utilisera moins de 4 Go, cela vous donne une marge de manœuvre et vous permet d’anticiper l’avenir au cas où vous auriez besoin d’ajouter d’autres flux de travail.
En outre, surveillez de près l’utilisation des ressources et utilisez un hébergeur n8n qui propose des plans facilement évolutifs, comme Hostinger. De cette façon, vous pouvez ajouter des ressources supplémentaires si votre installation d’automatisation nécessite plus de puissance de calcul que prévu.

Tout le contenu des tutoriels de ce site est soumis aux
normes éditoriales et aux valeurs rigoureuses de Hostinger.

Chaimaa est une spécialiste du référencement et du marketing de contenu chez Hostinger. Elle est passionnée par le marketing digital et la technologie. Elle espère aider les gens à résoudre leurs problèmes et à réussir en ligne. Chaimaa est une cinéphile qui adore les chats et l’analyse des films.