Quand on lance un crawl sur un site, le premier réflexe est souvent le même : on plonge dans la liste des codes HTTP, on filtre les 404, on traque les titles dupliqués, on vérifie que chaque page possède bien un H1. Ces analyses sont indispensables. Elles constituent le socle de tout audit technique sérieux et personne ne devrait s’en passer.
Mais la richesse d’un crawl ne s’arrête pas là. Derrière les indicateurs classiques se cachent des analyses moins courantes, qui apportent pourtant un éclairage précieux sur la santé réelle d’un site. Cet article en propose trois. Pas pour remplacer les vérifications habituelles, mais pour les compléter avec des angles d’analyse que vous n’exploitez peut-être pas encore.
Les exemples visuels de cet article sont tirés de Scouter, un crawler SEO open source et self-hostable. Mais les principes décrits ici s’appliquent quel que soit l’outil que vous utilisez.
Avant de rentrer dans le vif du sujet, un préalable s’impose.
Avant toute analyse : catégorisez vos URLs
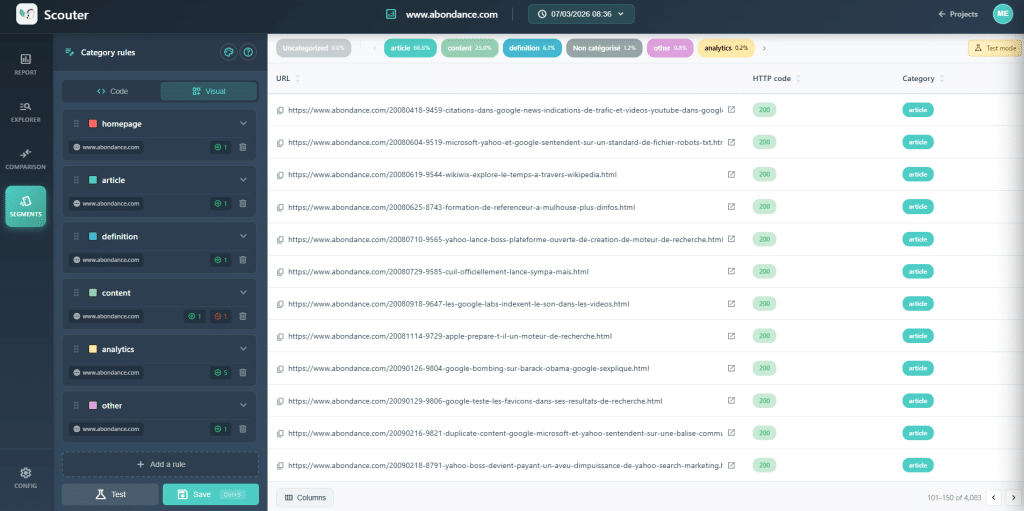
C’est le geste qui transforme un crawl brut en un outil de diagnostic. Avant d’analyser quoi que ce soit, la première étape consiste à regrouper vos URLs par template technique : fiches produit, pages catégorie, articles de blog, pages institutionnelles, etc. Sans ce découpage, vous travaillez à l’aveugle.
Pourquoi c’est indispensable ?
Prenons un exemple concret. Votre crawl remonte 30 % de H1 dupliqués sur l’ensemble du site. Le chiffre fait peur. Mais en l’état, il ne vous dit rien sur la cause du problème.
Maintenant, éclatez cette donnée par catégorie. Vous découvrez que la duplication touche massivement les fiches produit. L’hypothèse devient limpide : les déclinaisons (couleur, taille) génèrent un H1 identique parce que le variant n’est pas intégré dans le titre. La recommandation coule de source : modifier la règle de génération du H1 produit pour y injecter l’attribut de déclinaison (la couleur du produit par exemple).
Sur le template article, le même symptôme peut avoir une cause totalement différente : un mauvais balisage du template, un H1 codé en dur, un champ éditorial mal configuré. La recommandation sera donc elle aussi différente.
La logique à retenir : Constater l’anomalie → éclater par template → observer des exemples → comprendre le pattern → formuler une recommandation ciblée.
C’est cette démarche de catégorisation qui donne du sens à toutes les analyses qui suivent. Pensez-y comme un filtre que vous posez sur vos données pour passer du constat global à la compréhension fine.
1. La profondeur de crawl : un diagnostic express de votre architecture
Parmi les données remontées par un crawl, le niveau de profondeur des pages est sans doute l’une des plus parlantes. Beaucoup la survolent, se contentant de vérifier que les pages importantes ne sont « pas trop profondes ». C’est passer à côté de l’essentiel.
De quoi parle-t-on ?
Le niveau de profondeur d’une page correspond au nombre minimum de liens qu’il faut suivre depuis la page d’accueil pour y accéder. C’est le chemin le plus court, pas n’importe quel chemin. On parle souvent en « clics » pour vulgariser, mais ce sont bien les liens qui comptent. La homepage se situe au niveau 0, les pages qu’elle lie directement au niveau 1, et ainsi de suite.
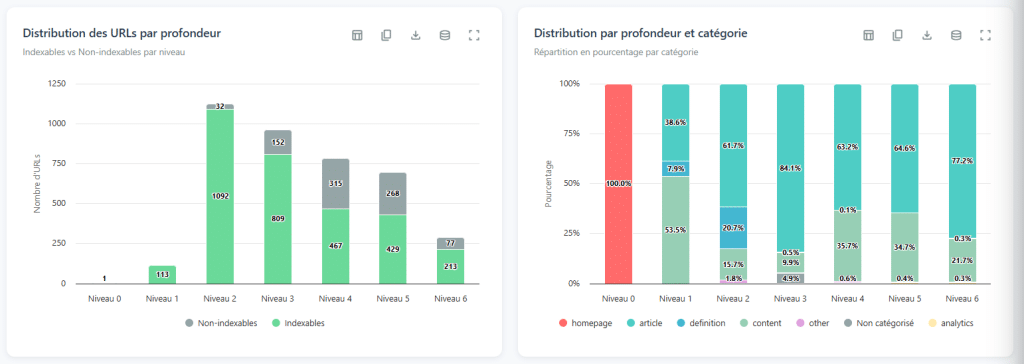
Lire la courbe de profondeur
L’intérêt de cette analyse ne réside pas dans les chiffres bruts mais dans la forme de la courbe de distribution. Rien qu’en la regardant, vous pouvez diagnostiquer des problèmes structurels majeurs.
Une courbe plate qui s’étire sur des dizaines de niveaux (des dizaines de niveaux ou plus, avec peu de pages à chaque étage) : c’est le signe quasi certain d’une pagination linéaire. Le site ne permet d’avancer que d’une page à la fois, page 1, page 2, page 3… Le crawler doit traverser chaque étape pour atteindre les contenus en fin de séquence. Résultat : les pages les plus profondes sont quasiment inaccessibles.
Une courbe à deux bosses (ça monte, ça descend, puis ça remonte à nouveau) : c’est le signal d’une section quasi-orpheline. La première bosse représente le cœur du site, bien maillé. La seconde correspond à un ensemble de pages qui n’est relié au reste que par quelques liens situés en profondeur. Si vous coupez ces rares liens, toute cette partie du site devient isolée. Conséquence : très peu d’accessibilité, très peu d’autorité transmise.
Trop de profondeur pour trop peu de pages (cinq niveaux pour seulement cinquante pages, par exemple) : il y a un problème d’efficacité dans le maillage interne. On devrait pouvoir rendre ces pages accessibles en bien moins de clics.
Oubliez la règle des « 3 clics »
La fameuse règle « tout doit être accessible en 3 clics maximum » est un mythe tenace. Imaginez un instant l’appliquer à Amazon ou à n’importe quel site de grande envergure : c’est tout simplement impossible. Plutôt que de s’accrocher à un nombre arbitraire, il est plus utile de raisonner en proportion.
Voici une base théorique simple pour évaluer si votre profondeur est cohérente. Partez du principe que la page d’accueil (niveau 0) fait découvrir environ 100 pages. Considérez ensuite que chaque nouvelle page découverte en fait elle-même découvrir 10 en moyenne. On obtient : environ 100 pages au niveau 1, 1 000 au niveau 2, 10 000 au niveau 3.
L’idée n’est pas de coller exactement à ce modèle, mais de comparer votre profondeur réelle à cette base théorique. Si votre site compte 500 pages et que vous avez déjà 5 niveaux de profondeur, il faut investiguer le maillage car on pourrait couvrir ces pages avec seulement 2 niveaux de profondeur en théorie.
2. Le near duplicate : la duplication invisible
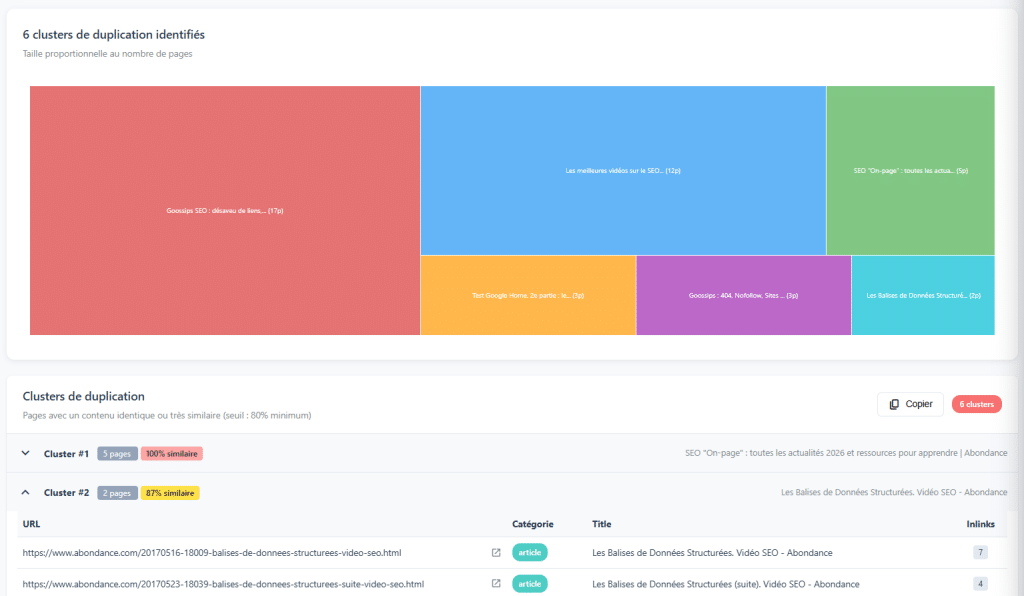
En matière de duplication de contenu, tout le monde connaît le DUST (Duplicate URL, Same Text) : deux URLs différentes qui servent exactement le même contenu. C’est facile à détecter et généralement simple à corriger. Mais il existe une forme de duplication bien plus insidieuse : le near duplicate.
Des pages qui se ressemblent un peu trop
Le near duplicate désigne des pages dont le contenu est très proche sans être strictement identique. Quelques mots qui changent, un paragraphe en plus ou en moins, une reformulation légère… mais un fond essentiellement similaire. Les algorithmes de détection (comme le Simhash utilisé par de nombreux crawlers) identifient ces proximités en comparant les empreintes des contenus.
Ces pages posent un vrai problème. Elles diluent l’autorité entre plusieurs URLs au lieu de la concentrer sur une seule. Elles se cannibalisent en positionnement. Et elles envoient à Google un signal de contenu à faible valeur ajoutée. Dans certains cas, la bonne décision est de fusionner ces contenus en une seule page, plus riche et plus pertinente.
Attention aux faux positifs
C’est un point de vigilance important : toute proximité de contenu n’est pas forcément un problème.
Si vous gérez un site multilingue avec des versions en-GB et en-US, il est parfaitement normal que ces pages soient quasi identiques. Elles ne s’adressent pas au même marché. Même logique pour les pages géolocalisées : « plombier Paris » et « plombier Lyon » partageront souvent un template identique avec des variations mineures, et c’est voulu.Le near duplicate est un signal à investiguer, pas un verdict automatique. C’est l’analyse manuelle derrière qui détermine s’il s’agit d’un problème réel ou d’un faux positif lié au contexte du site.
3. La structure Hn : vos H2, H3, H4… sont-ils vraiment en ordre ?
Quand on audite le balisage d’un site, le réflexe est de vérifier le H1 : est-il présent ? Unique ? Pertinent ? C’est bien. Mais la structure de titres d’une page ne se résume pas à son H1. C’est toute la hiérarchie (du H1 au H6) qui organise le contenu et aide les moteurs à en comprendre le contenu.
Les problèmes invisibles à l’œil nu
Analyser la structure Hn complète à l’échelle d’un crawl permet de détecter des anomalies systémiques que la simple vérification du H1 ne révèle pas.
Des sauts de niveaux, d’abord : une page qui passe d’un H1 directement à un H3 sans H2 intermédiaire. C’est une rupture dans la logique hiérarchique du document. Des H1 absents alors que des H2 sont présents, une incohérence structurelle fréquente. Des structures complètement anarchiques, signe d’un template mal conçu ou d’un contenu balisé sans méthode.
Il y a aussi la duplication massive de H2, un symptôme souvent invisible quand on ne regarde que les H1. Elle peut révéler un problème de template : des blocs réutilisés d’une page à l’autre (widgets, modules de sidebar, footer balisé en H2…) qui polluent la structure de titre de chaque page.
Pourquoi c’est important
Google utilise les balises Hn pour comprendre la structure thématique d’une page. Une hiérarchie cohérente aide les moteurs à identifier les sujets principaux et secondaires abordés. Au-delà du SEO, c’est aussi une question d’accessibilité : les lecteurs d’écran s’appuient sur cette hiérarchie pour naviguer dans le contenu.
L’intérêt majeur de cette analyse à l’échelle du crawl, c’est qu’elle pointe vers des défauts de templates. Un problème de structure Hn qui se répète sur des centaines de pages, c’est presque toujours un problème de template à corriger une seule fois pour un impact massif.
En résumé
Ces trois analyses ne remplacent pas les vérifications classiques d’un audit technique. Elles les complètent. Ce sont des angles d’observation qui, une fois maîtrisés, élargissent considérablement la portée de ce que vous pouvez diagnostiquer à partir d’un simple crawl.
Le point essentiel à retenir dépasse ces trois exemples : un crawl n’est pas une fin en soi, c’est un outil de diagnostic. Les données brutes ne valent rien sans interprétation. La vraie valeur d’un audit technique, c’est la capacité à lire les patterns, comprendre les causes, et formuler des recommandations actionnables. Et tout commence par un bon réflexe : catégoriser avant d’analyser.
Les illustrations de cet article ont été réalisées avec Scouter, un crawler SEO open source et self-hostable, disponible sur lokoe.fr/crawler-seo-scouter.