Que se passe-t-il lorsque vous vous fixez pour objectif d’augmenter la capacité du chemin de traitement des données critiques de Taboola, qui a désespérément besoin de plus de jus ? Vous bénéficiez d’un gain de performances x2 !
Dans cet article de blog, nous décrirons comment Charles de l’équipe d’algorithmes, Gilad – notre chef d’équipe de cloudification et moi-même de la plate-forme de données, avons réussi à doubler le débit de notre pipeline de formation en apprentissage automatique.
Taboola, traitant des centaines de To de données quotidiennes, dispose de nombreux pipelines de traitement de données différents, où interviennent généralement des disciplines de divers domaines. L’un de ces pipelines de traitement de données, que nous décrirons dans ce blog, exécute de nombreux algorithmes d’apprentissage automatique intenses sur d’énormes quantités de données de production. Cet important pipeline est utilisé pour obtenir des informations commerciales sur la manière dont les utilisateurs et les sites de Taboola interagissent les uns avec les autres. Son résultat se traduit ensuite par l’amélioration de la qualité de nos modèles de recommandation, le cœur même de notre métier.
Afin de pouvoir traiter plusieurs To de nouvelles données chaque heure, nous utilisons tous les types de mots à la mode logiciels et matériels, tels que Kubernetes, Volcano, les frameworks d’apprentissage automatique fonctionnant sur des clusters CPU et GPU hétérogènes.
L’amélioration des performances du pipeline d’apprentissage automatique se traduit directement par un débit accru lors de la formation de nos différents modèles de recommandation. Cela se traduit également par une réduction des coûts matériels. Un autre effet secondaire très important est le fait que notre équipe d’algorithmes peut désormais exécuter et tester plus d’algorithmes (et différents) sur le même matériel, améliorant ainsi encore plus notre moteur de recommandation AI.
Alors, plongeons dans les détails techniques de la façon dont nous avons accompli cela.
Analyse initiale des performances
Taboola forme bon nombre de ses grands réseaux TensorFlow sur des clusters hétérogènes de GPU sur site composés de plus d’une centaine de GPU P100, V100 et A100. Nous réentraînons quotidiennement tous les réseaux sur les données réelles, en direct et de production. Évidemment, ce processus prend beaucoup de temps et de ressources.
Afin d’améliorer les performances du cluster et d’optimiser son travail, principalement pour terminer les travaux dans les délais souhaités, nous avons décidé de lancer un effort d’analyse des performances et d’explorer les opportunités d’optimisation à court et à long terme que nous pouvons utiliser.
L’analyse des performances initiales nous a montré que les réseaux TensorFlow ne tiraient pas pleinement parti des capacités des GPU.
Les GPU étaient relativement sous-utilisés comme le montre l’outil nvidia-smi. La charge initiale était d’environ 30 à 40 % pendant les heures de pointe. Le profilage du réseau pendant sa formation, à l’aide de l’outil nvprof de NVIDIA, nous a assuré qu’il y avait des lacunes importantes dans la chronologie où le GPU était inactif ou pas pleinement utilisé. Les emplacements vides dans la sortie nvprof de NVIDIA dans la figure 1 indiquent exactement le pourcentage d’inactivité du GPU sur l’ensemble de la chronologie.
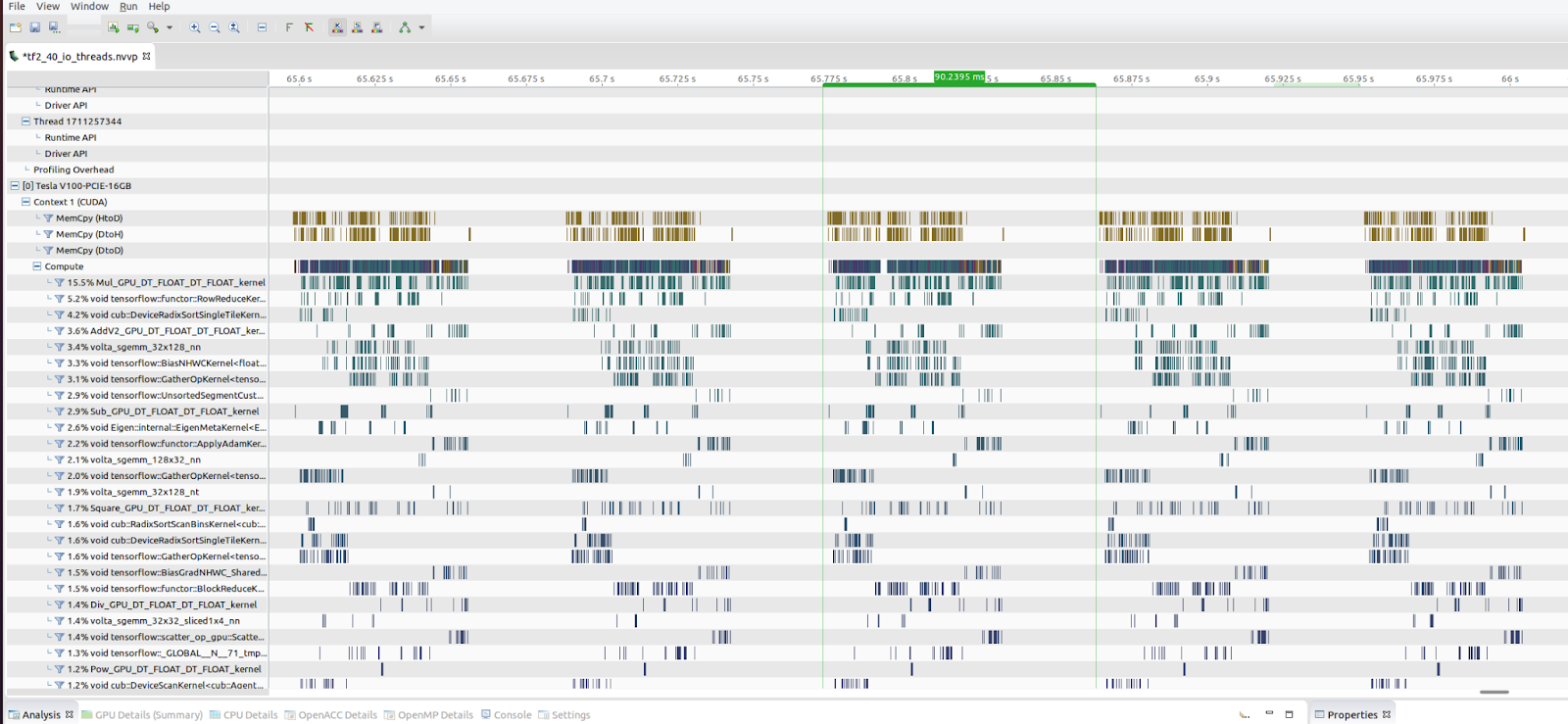
En plongeant un peu plus dans le code, nous avons vu qu’une opération TensorFlow chronophage s’exécutait entièrement sur le CPU et non sur le GPU. À ce stade, nous avons commencé à rechercher des optimisations à portée de main que nous pourrions utiliser. Après tout, l’idée est d’obtenir autant de temps d’exécution dans le GPU et de laisser le CPU gérer le système d’exploitation, les IOP et le chemin du code.
Nous avons remarqué que l’implémentation par défaut de TensorFlow utilise près de 100 % de la VRAM GPU lors de l’initialisation. Nous avons commencé à nous demander si l’allocation de l’intégralité de la VRAM du GPU était obligatoire pour que le réseau fonctionne et si nous pouvions presser deux entraînements simultanés en même temps sur le même GPU.
Il est vite devenu clair que nous pouvions réduire les besoins en mémoire, par entraîneur, à un peu moins de la moitié des 16 Go installés dans les GPU P100 et V100, en utilisant le fragment de code suivant :

Nous avons laissé les différents entraîneurs fonctionner avec cette configuration pendant quelques jours en production pour vérifier qu’ils fonctionnent comme prévu, qu’ils ne plantent pas et qu’ils donnent les bons résultats algorithmiques. Une fois que nous avons pu constater que c’est le cas, nous avons pu passer à l’étape suivante.
L’étape suivante consistait à lancer simultanément deux réseaux différents sur chaque GPU, chacun prenant 40% de la VRAM du GPU. Il ne s’agit pas d’une solution « manuel » car les deux trainers seront synchronisés par le pilote NVIDIA et les choses ne fonctionneront pas vraiment simultanément sur le GPU. Cependant, comme une partie du temps du formateur est consacrée à la récupération de données à partir d’un serveur HDFS distant, d’opérations CPU, etc., nous espérions que tous ces composants se chevaucheraient et que nous améliorerions le débit global.
Mettre tous ensemble
Effectivement, nous avons pu réaliser des gains de performances (presque le double des performances) en utilisant cette technique. Cela signifiait effectivement que nous pouvions exécuter deux fois plus de travail sur le même nombre de GPU sans ajouter de nouveau matériel et respecter nos délais de production en exécutant tous les réseaux de l’équipe d’algorithmes dans les délais requis.
La figure 2 montre comment le nombre de formateurs a augmenté une fois que nous avons ouvert la fonctionnalité GPU partagée en production. La ligne horizontale orange indique le nombre physique réel de GPU dans le cluster. Le côté gauche du graphique montre le nombre de formateurs fonctionnant simultanément dans le cluster, avant notre optimisation. Le côté droit indique le nombre de trainers exécutés simultanément après l’activation du mode GPU partagé. Comme on peut le voir, nous avons pu traiter deux fois plus de trainers sur le même matériel qu’auparavant.
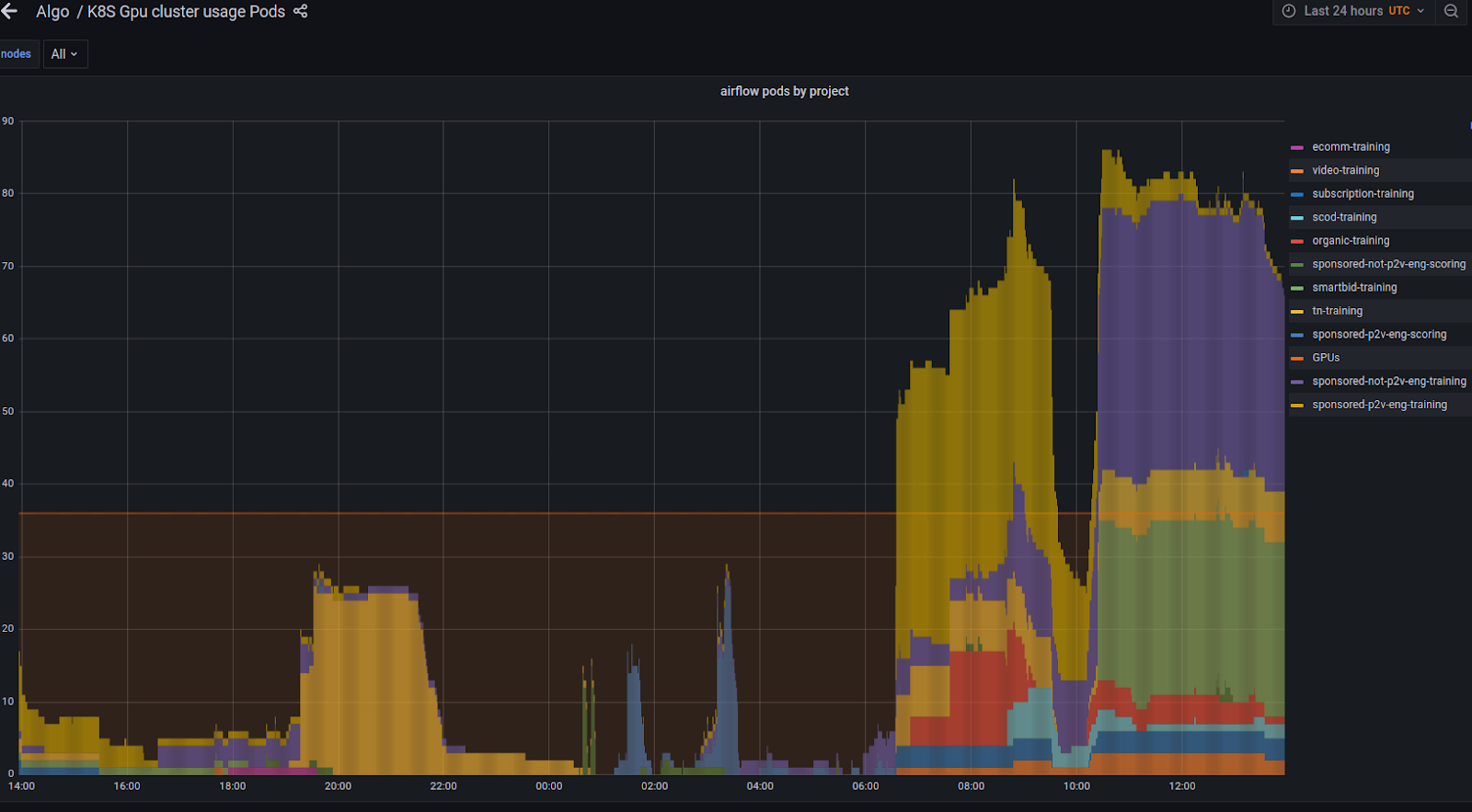
À l’avenir, nous prévoyons d’étudier quelles parties des opérations réseau peuvent être optimisées davantage et, plus important encore, lesquelles s’exécutent sur le CPU et peuvent être migrées vers le GPU.
Il était maintenant temps de le tester dans un environnement de production pour tester tous les changements de code et de configuration pour voir si nous avions réellement gagné en performances.
Magie de la cloudification
La prochaine chose à implémenter était de configurer le système pour qu’il fonctionne comme il le ferait en production, c’est-à-dire planifier deux réseaux TensorFlow simultanément sur la même machine. Volcan et l’équipe de cloudification de Taboola à la rescousse.
Taboola utilise un Kubernetes cluster pour gérer une partie importante de nos serveurs CPU et GPU. La formation ML de l’équipe de l’algorithme se déroule sur les différents jobs Kubernetes. Le contrôleur de tâches Kubernetes crée un pod TensorFlow qui est planifié en fonction d’un GPU allouable à un nœud.
Lorsque nous avons commencé à examiner les options de mise en œuvre de la planification de deux pods exécutés simultanément sur la même machine physique et le même processeur graphique, nous avons réalisé que nous avions besoin d’une couche de gestion supplémentaire pour nous permettre de le faire.
Il y avait quelques outils open source disponibles pour permettre cela. Le premier outil que nous avons examiné était Volcan, un système de planification par lots natif du cloud pour les charges de travail gourmandes en ressources de calcul. L’autre option que nous avons envisagée était le plugin d’appareil d’Alibaba et le plugin d’appareil Nvidia avec la fonction CUDA Time-Slicing. Après un processus d’évaluation rapide, nous avons décidé d’opter pour Volcano. Volcano nous a permis d’implémenter la planification basée sur la mémoire GPU différemment de l’approche standard de planification basée sur le calcul GPU. Le projet Volcano a été accepté pour CNCF le 9 avril 2020 et est au niveau de maturité du projet en incubation. Il prend également en charge les frameworks informatiques populaires tels que TensorFlow et Spark, deux technologies que nous utilisons beaucoup, et cela semblait être un choix raisonnable.
La planification de deux processus simultanés sur la même machine physique et le même GPU est basée sur la taille de la mémoire du GPU. Depuis que nous avons découvert qu’environ 40 % des 16 Go de RAM du GPU étaient suffisants pour un seul entraîneur standard, nous avons basé la planification sur ce paramètre, ce qui nous donne la possibilité d’allouer une plus grande partie de la mémoire aux modèles « plus lourds » et de les programmer parallèlement. modèles d’utilisation de la mémoire plus petits. Ainsi, l’utilisation totale du périphérique GPU sera plus élevée. Nous utilisons la variable d’environnement Volcano pour calculer la configuration de la fraction de mémoire TensorFlow 1 ou définir la configuration de la mémoire du périphérique virtuel TensorFlow 2 :

L’un des problèmes de mise en œuvre que nous rencontrons dans le processus est MIG (GPU multi-instance) GPU activés comme le Nvidia A100. Les plugins de périphérique GPU exposent la ressource à Kubernetes et attribuent le GPU au conteneur en fonction de l’index de périphérique. Dans les GPU compatibles MIG, toutes les instances MIG partagent le même index du périphérique GPU physique. Nous avons réglé le plug-in de l’appareil Volcano pour utiliser le GPU et l’UUID de l’instance MIG comme identifiant unique. Taboola a fait avancer cet effort et a créé ce demande d’extraction qui est encore un travail en cours, mais il est stable dans un grand environnement de production pendant assez longtemps.
La figure 3 montre un fichier de configuration yaml typique qui utilise Volcano pour atteindre notre objectif.

À l’avenir, nous étudions les mécanismes de mise en file d’attente Volcano pour mieux prendre en charge les charges de travail de remplissage telles que les tâches de réglage d’hyperparamètres volumineux.
Dernières pensées
Taboola traite d’énormes quantités de données chaque heure, plusieurs To de données, et cela nécessite évidemment un pipeline complexe et efficace pour traiter toutes ces données. L’un de ces pipelines exécute nos modèles ML encore et encore pour nous permettre de mieux comprendre ce qu’il faut afficher aux utilisateurs à chaque instant et sur chaque site.
Nous exécutons nos modèles ML à l’aide d’un environnement logiciel et matériel complexe comprenant plus de 100 GPU NVIDIA orchestrés par kubernetes, Volcano, Dockers, TensorFlow et d’autres composants logiciels. Afin d’extraire plus de jus de ces pipelines, nous avons continué à optimiser l’utilisation du GPU, après avoir identifié qu’ils étaient sous-performants.
Nos efforts ont porté leurs fruits et nous avons atteint un très bon débit x2 en utilisant le même matériel. Nous avons effectivement gagné x2 le nombre de GPU pour “gratuitement”.
Nos objectifs à plus long terme sont de réduire davantage les performances de l’écosystème, par exemple en optimisant notre pipeline ML, en migrant vers Keras, en explorant la migration des composants CPU ML vers le GPU et en explorant également l’amélioration des opérations d’E/S.