
Depuis plusieurs mois, Damien Andell (1492.vision) et Olivier de Segonzac (RESONEO) décortiquent le code de Google Search et Google Discover. Ils ont mis en commun leurs travaux de recherche et vous dévoilent, aujourd’hui, une partie de leurs découvertes majeures. Tout ne peut pas être exposé, mais Damien et Olivier mettent ici en lumière des informations qui permettent de mieux comprendre comment Google génère et classe ses résultats. On leur laisse la parole.
Les informations présentées proviennent exclusivement de sources publiques accessibles sans contournement d’accès ni intrusion. Elles sont publiées à titre informatif.
1200 expérimentations : le laboratoire permanent de Google
Nous avons obtenu la liste des 1200 expérimentations Google dont plus de 800 actives en juin 2025. Cette découverte confirme d’abord que de nombreux composants révélés dans les leaks de 2024 restent au cœur du système : Twiddlers, QRewrite, Tangram, QUS et d’autres !
Mais cette liste apporte aussi son lot de nouveaux noms de code intrigants :
- De Harmony à Thor, en passant par des appellations poétiques comme Whisper, Moonstone ou Solar.
- On y trouve également DeepNow, le successeur de Google Now, et son pendant NowBoost.
- Ou encore SuperGlue, qui pourrait bien remplacer Glue, l’équivalent de NavBoost pour la recherche universelle.
Ci-dessous le tag cloud de la liste complète des expérimentations, donnant une idée des composants sur lesquels Google porte ses efforts actuellement :

Google opère par micro-changements, en continu
Contrairement à la majorité des sites web qui procèdent par grandes refontes tous les 3-5 ans, Google privilégie l’évolution permanente. Pas de grand soir, pas de “nouvelle version” annoncée en fanfare, mais un flux continu de micro-changements qui passent progressivement du statut “experiment” à “launch” avant leur intégration complète.
Cette approche explique la stratification temporelle de cette liste : des expérimentations datant de plusieurs mois côtoient des tests tout frais, certains atteignant leur Nième itération (comme MagitCotRev15Launch). Cette méthode permet à Google de minimiser les risques – si une expérimentation échoue, seule une fraction des utilisateurs est impactée – tout en maintenant une vitesse d’innovation impossible avec des refontes classiques.
La diversité des domaines couverts impressionne
L’IA avec les multiples variantes de Magi et Aim (AI Mode), le shopping avec plus de 50 expérimentations dédiées, les différentes verticales comme le sport avec des tests spécifiques pour chaque discipline majeure, ou encore la finance, la météo, le travel…
Particularité intéressante : la présence systématique de “domains” pour chaque verticale (ShoppingOverlappingDomain, TravelOverlappingDomain, SportsOverlappingDomain…). Ces “Overlapping Domains” indiquent un système sophistiqué où chaque équipe produit dispose de son propre espace d’expérimentation, permettant de gérer les interactions entre tests sans créer de conflits.
La liste complète des expérimentations, compilées par Résoneo : https://i-l-i.com/google-experiments-list-june2025.html
Entities everywhere
“Entities everywhere”, c’est le nom de la conférence donnée par Damien et Sylvain de 1492.vision en début d’année à Marseille : une analyse approfondie du rôle central des entités et du Knowledge Graph dans l’écosystème Google.
Grâce à leurs investigations, nous savons désormais que le Knowledge Graph dépasse largement son rôle apparent d’assistant affichant des panneaux informatifs. Il constitue le système nerveux central de tout l’écosystème Google, alimentant Search, Discover, YouTube, Maps, Assistant, et désormais Gemini et AI Overviews.
Le système Livegraph - le cœur battant du Knowledge Graph
Livegraph attribue un poids de confiance à chaque triplet qu’il rencontre avant de décider de l’intégrer ou non. Cette obsession de la vérification se reflète dans une hiérarchie de namespaces à plusieurs niveaux :
- kc : données issues de corpus hautement validés (par ex. âges officiels, registres gouvernementaux)
- ss : “webfacts” extraits du web, complétés par quelques ok : shortfacts (moins fiables mais plus riches)
- hw : informations soigneusement curées par des humains
Cette classification est loin d’être cosmétique ; elle détermine directement le niveau de confiance que Google accorde à chaque fait et la manière dont celui‑ci est utilisé dans ses différents services.
Des entités flottantes pour accélérer le traitement des événements émergents
La découverte des “entités fantômes”, ces entités non ancrées flottant dans une zone tampon du Knowledge Graph, s’avère particulièrement fascinante. Contrairement aux entités officielles dotées d’un identifiant MID stable, ces structures temporaires permettent à Google de réagir en temps quasi-réel aux événements émergents. Pendant que les LLMs classiques restent figés dans leurs données d’entraînement, Google peut instantanément intégrer de nouvelles entités, les valider progressivement, et les propulser dans ses résultats. Les systèmes SAFT et WebRef révélés par les leaks de 2024 fonctionnent en continu pour extraire, classifier et relier ces entités, construisant une représentation sémantique complète du web.
Devenir une entité validée : l’enjeu SEO majeur des éditeurs
Pour les professionnels du SEO, l’enjeu devient clair : devenir une entité validée dans ce graphe omniscient.
Le leak de 2024 avait montré que Google vectorise des sites entiers, calculant des scores de cohérence thématique (siteFocusScore, Nsr…) qui peuvent pénaliser les sites dispersés. Les données Chrome alimentent continuellement ce Knowledge Graph, détectant les entités visitées, calculant des scores de confiance, identifiant les tendances émergentes. Dans cette nouvelle réalité, la visibilité dépend moins de la capacité à produire du contenu que de l’aptitude à exister en tant qu’entité validée, triangulée par des sources multiples, et profondément ancrée dans son graphe thématique.
→ Lire l’article complet sur les entités sur 1492.vision
L’offensive IA : 90 projets Google en développement simultané
Une autre découverte nous a permis d’accéder à ce qui semble être un menu de debug réservé aux employés Google, accessible uniquement “on corp or vpn”. Tom Critchlow avait déjà identifié une version antérieure en mars dernier.
Cette nouvelle version, datant du 28 mai 2025, dévoile près de 90 projets en développement (près de 50 nouveautés par rapport à la version précédente !). L’approche multi-agents adoptée frappe d’emblée : plutôt qu’un assistant généraliste unique, Google développe une constellation d’agents ultra-spécialisés – MedExplainer pour le médical, Travel Agent pour les voyages, Neural Chef pour la cuisine, Shopping AI Studio pour le commerce, etc.
50 tests actifs pour l’AI Mode
En parallèle, de nombreuses expérimentations correspondent au projet Magi (nom interne de l’AI Mode), avec plus de 50 tests actifs. L’analyse montre une progression méthodique :
- MagiModelLayerDomain comme infrastructure de base.
- MagitV2p5Launch pour Gemini 2.5.
- SuperglueMagiAlignment faisant écho au système Glue de tracking des interactions.
Particulièrement notable : MagitCotRev15Launch, déjà à sa 15ème révision, implémentant la technique “Chain of Thought” où l’IA expose son raisonnement en cinq étapes (Réflexion → Recherche → Lecture → Synthèse → Polissage).
Voici un aperçu de la liste des expérimentations du projet Magi :

Des réflexions internes dans la manière dont l’IA transforme notre expérience de recherche
Le projet AIM (AI Mode) développe l’interface utilisateur avec des points d’entrée multiples :
- AimLhsOverlay pour une sidebar IA,
- SbnAimEntrypoints transformant le bouton “J’ai de la chance” en porte d’entrée IA,
- jusqu’au logo Google lui-même devenant interactif.
Les projets “Stateful Journey” et “Context Bridge” confirment la révolution des LLMs : Google ne traite plus des requêtes isolées mais des sessions conversationnelles complètes.
Pour les professionnels du SEO, ces observations imposent plusieurs adaptations : l’hyper-spécialisation devient cruciale face à des agents experts, la multi-modalité n’est plus optionnelle, et la personnalisation atteint des niveaux inédits.
→ Lire l’article complet sur la stratégie IA de Google sur resoneo.com
La machine à profiler : souriez, vous êtes embeddés !
Nos investigations dévoilent également l’architecture secrète qui transforme chaque interaction numérique en embeddings mathématiques – des vecteurs capturant l’essence de votre identité digitale.

Au cœur de ce dispositif : Nephesh, la fondation universelle des embeddings utilisateur chez Google, générant des représentations vectorielles de vos préférences à travers TOUS les produits du géant. Les leaks de 2024 avaient déjà exposé des signaux mesurant si vous êtes un profil type ou atypique et d’autres prédisant votre probabilité d’aimer un contenu via l’alignement vectoriel entre vos goûts et le contenu.
Un embedding long terme et un embedding temps réel pour construire votre profil Discover
L’architecture complète dépasse l’entendement. Pour Discover, Google déploie un duo d’embeddings aux noms d’artistes : Picasso et VanGogh (noms modifiés pour préserver leur anonymat…).
Picasso incarne votre mémoire longue durée, analysant patiemment des mois d’interactions pour construire votre profil vectoriel persistant via deux fenêtres temporelles : STAT pour vos intérêts récents, LTAT pour vos passions durables.
VanGogh fonctionne directement sur votre appareil, capturant en temps réel l’état de votre device, vos dernières requêtes, même la profondeur de votre scroll ! Ces deux systèmes s’orchestrent pour naviguer entre vos besoins immédiats et vos intérêts profonds.
Hulk : l’analyse comportementale de Discover
Au-delà de Picasso-VanGogh, Google déploie une constellation d’embeddings spécialisés : verticaux (podcasts, vidéos, shopping, voyages), temporels (temps réel, court terme, permanent), et contextuels.
Le système HULK pousse l’analyse comportementale à l’extrême :
- Il détecte précisément si vous êtes IN_VEHICLE, ON_BICYCLE, ON_STAIRS, IN_ELEVATOR, ou même SLEEPING !
- Il identifie vos lieux habituels (SEMANTIC_HOME, SEMANTIC_WORK), prédit vos destinations futures, et adapte tout en conséquence.
Pour les créateurs de contenu, le paradigme change radicalement : vos contenus sont désormais évalués sur leur alignement vectoriel avec ces profils utilisateurs multidimensionnels.
→ Lire l’article complet sur les embeddings sur 1492.vision
Compréhension des requêtes : query expansion et scoring révélés
Une autre trouvaille notable concerne le système de query expansion de Google et un mystérieux scoring en temps réel. Via une méthode que nous garderons confidentielle (*), nous avons accès à la transformation de vos requêtes.
La transformation des requêtes pour le query expansion
Exemple concret : “coffre de toit” devient instantanément “coffredetoit” (trigramme consolidé), puis s’étend vers “coffres”, “toits”, “toiture”. Des marqueurs spécifiques apparaissent : iv;p et iv;d (“in verbatim”) – le premier pour les correspondances exactes, le second pour les dérivations linguistiques.
Un autre exemple de query expansion pour “tour”, “moto” ou encore “hollande” :

Une sophistication remarquable dans le traitement géographique
Par exemple, pour “nail salon fort lauderdale 17th street”, le système utilise :
- des catégories géographiques (geo:ypcat:manicuring),
- des codes de zones (geo;88d850000000000),
- et étend les formes d’adresses.
Exemple de query expansion sur la géolocalisation :
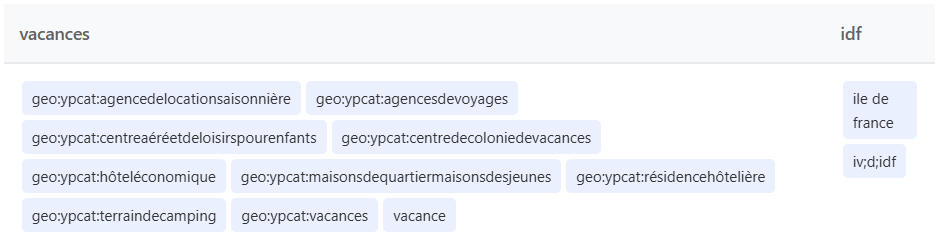
Détail révélateur : selon votre localisation, certains termes sont automatiquement traduits pour capturer des résultats locaux, même si ce n’est pas votre langue par défaut.
Ces observations confirment l’architecture décrite dans les Google Leaks 2024 – comme le pipeline GWS → Superroot → Query Understanding Service → QBST – reste actif, avec des expérimentations continues (GwsLensMultimodalUnderstandingInQusUpstream, QusPreFollowM1InQResS…).
Un scoring de 0 à 10 appuyant la documentation des termes saillants
La même brèche expose un système de scoring : chaque terme reçoit un score de 0 à 10 points par URL. Les patterns sont cohérents : stop-words ignorés, termes du title avec bonus, entités nommées avec scores maximaux. L’aspect crucial reste la nature pairwise : un même terme obtient des scores différents pour une même URL selon le contexte de la requête.
Voici des exemples de scoring par terme, pour chaque URL :
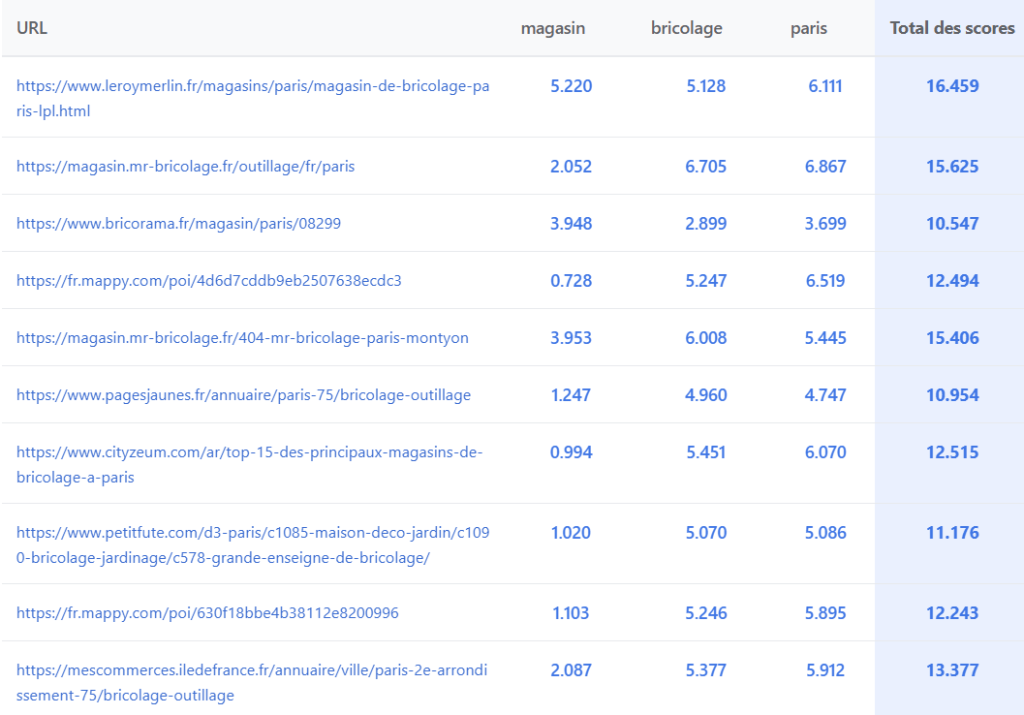
Cette observation valide la documentation des “Salient Terms” : Google calcule une pondération contextuelle via multiples signaux (virtualTf, idf, salience). Ces scores lexicaux ne déterminent pas le classement final – NavBoost, fraîcheur et autres facteurs restent prépondérants – mais cette fenêtre éclaire précieusement l’interprétation et la pondération des requêtes en temps réel.
(*) si vous cherchez, vous trouverez, mais gardez le secret pour préserver cette fenêtre d’observation 😀
→ Lire l’article sur les query expansions et le scoring de Google sur resoneo.com
Que retenir de ces découvertes et quel impact pour les référenceurs ?
La confirmation de l’existence de NavBoost était déjà une satisfaction en soi. Désormais, on en sait un peu plus sur la manière dont Google perçoit le web : un vaste graphe d’entités, hiérarchisées par niveaux de fiabilité; évoluant en temps réel au fil de milliers d’expérimentations simultanées; et des produits Google interconnectés (Search & Discover fonctionnant de pair comme l’avaient déjà repéré certains experts Discover).
Le SEO technique reste le socle indispensable pour que les moteurs accèdent à vos contenus, l’éditorial et le multi-modal ajoutent la couche de pertinence, la popularité et la compréhension des utilisateurs achèvent la liste des priorités 2025.
La clé pour les SEO ? Devenir une entité validée du Knowledge Graph, renforcer sa légitimité dans sa niche et optimiser simultanément contenu et expérience utilisateur.
Continuez à explorer le sujet :
👀 Graph Foundation Model : le nouvel algorithme de Google – Abondance – juillet 2025
👀 Knowledge Graph : le moteur caché derrière l’IA de Google – Abondance – juin 2025
👀 MUVERA : l’algorithme de Google qui promet une recherche optimisée – Abondance – juin 2025