
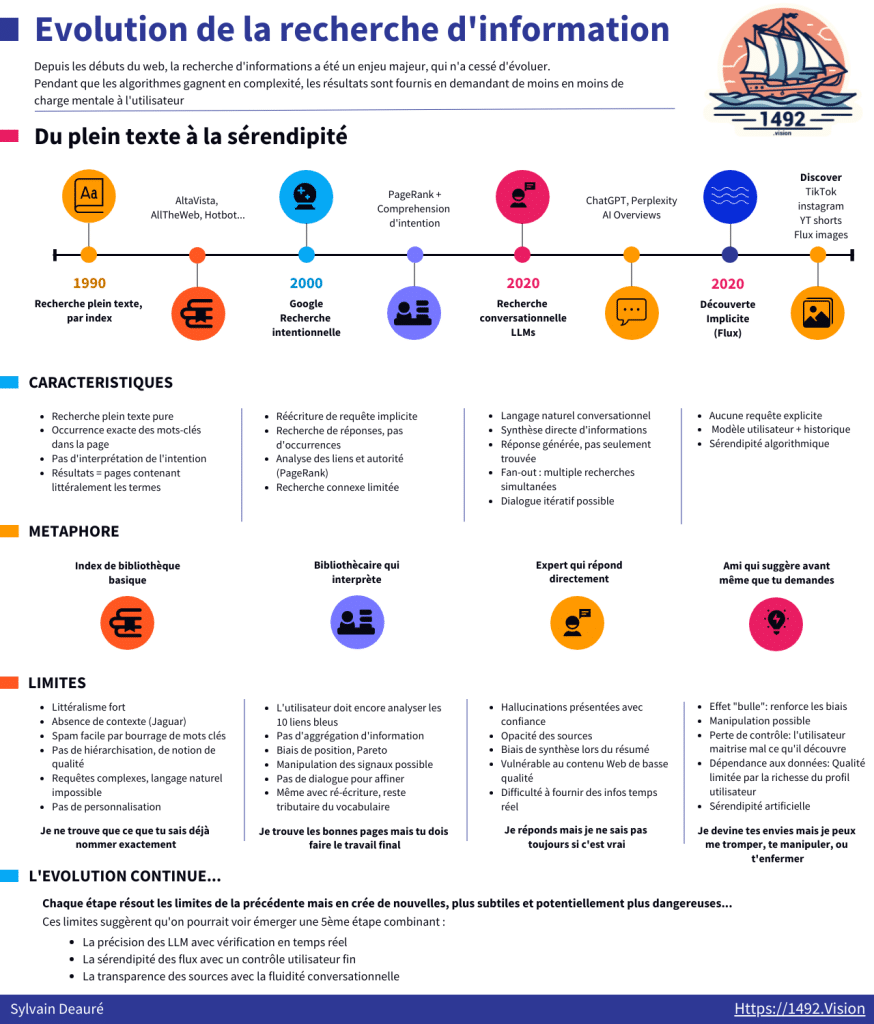
En trente ans, nous sommes passés d’index rudimentaires à des flux qui devinent nos envies. Pour les médias, les marques et le SEO, ce glissement change tout : l’effort cognitif demandé à l’utilisateur diminue à chaque étape, tandis que la part de l’algorithme augmente. L’infographie associée résume cette trajectoire en quatre phases. Sylvain Deauré, co-fondateur de 1492.vision nous propose le récit complet de cette évolution, avec les implications concrètes.
Pourquoi cette évolution compte
La recherche n’est plus seulement une liste de liens. Elle interprète, répond… puis anticipe.
Cette trajectoire suit trois sauts conceptuels majeurs :
- De « trouver des pages » à « générer des réponses » ;
- D’une logique centrée sur le mot-clé à une logique d’entités et d’intentions ;
- De l’action explicite (« je tape une requête ») à la découverte implicite (« on me propose avant que je demande »).
1. Recherche par index (années 1990)
Cette recherche s’apparente à un index de bibliothèque. On cherche un mot, on obtient des pages où il figure littéralement.
Caractéristiques clés de la recherche par index :
- Une recherche plein texte, sens littéral ;
- L’importance brute de la fréquence des mots ;
- Aucune compréhension d’intention.
Limites de l’approche :
- Littéralisme absolu (synonymes, ambiguïtés comme « jaguar » non gérés) ;
- Spam de mots-clés efficace ;
- Pas de personnalisation ni de hiérarchisation robuste.

On ne peut trouver bien que ce qu’on connaît et qu’on peut nommer.
Quelques repères historiques : W3Catalog (1993), WebCrawler (1994), Lycos (1994), AltaVista (1995). Ces pionniers du web ont popularisé l’indexation full‑text à grande échelle.
2. Recherche intentionnelle (années 2000, Google)
La recherche intentionnelle est comme un bibliothécaire qui comprend ce que vous voulez vraiment. Avec PageRank et la compréhension d’intention, Google bascule la logique : on ne cherche plus seulement des occurrences, on vise des réponses probables.
Caractéristiques de la recherche intentionnelle :
- Réécriture implicite de requêtes ;
- Évaluation de l’autorité via les liens ;
- Premiers indices de « recherche connexe » ;
- Émergence d’une économie du clic où les premiers résultats captent l’attention.
Limites de l’approche :
- L’utilisateur doit encore analyser les « 10 liens bleus » ;
- Pas de synthèse multi‑sources, peu de dialogue ;
- Vulnérabilité aux biais de position et aux manipulations SEO.
Laisse à l’utilisateur le soin de trouver la réponse dans les 10 liens bleus.
L’impact de la recherche intentionnelle sur le SEO : passage d’une optimisation « mots » à une optimisation « intentions + entités ». Structuration, E‑E‑A‑T, données structurées et qualité éditoriale deviennent décisives.
3. Recherche conversationnelle (années 2020, LLM)
La recherche conversationnelle, c’est un expert qui répond directement. Les modèles conversationnels effectuent un « fan‑out » de requêtes, agrègent et rédigent une réponse en langage naturel. L’expérience devient « dialogique ».
Caractéristiques de la recherche conversationnelle :
- La forme : langage naturel, itérations rapides ;
- Une synthèse directe d’informations ;
- De multiples recherches parallèles sous le capot ;
- L’adoption massive de quelques acteurs (ex. chatbots généralistes et spécialisés).
Limites de l’approche :
- Hallucinations et opacité des sources ;
- Coût énergétique et économique supérieur à la recherche classique ;
- Dépendance à la qualité du web indexé et au signal éditorial.

L’impact de la recherche conversationnelle sur le SEO : le but est d’écrire « pour la réponse » et non seulement « pour la page ». Il faut des contenus nativement synthétisables (titres informatifs, paragraphes denses, tableaux, FAQ), des données vérifiables et des sources claires. La marque sert de garantie de fiabilité.
4. Découverte implicite (flux personnalisés)
La découverte implicite, c’est cet ami qui vous suggère des contenus sans que vous ne demandiez rien. Google Discover, TikTok, YouTube ou Instagram s’appuient sur un modèle utilisateur (historique, interactions, centres d’intérêt) pour alimenter un flux continu.
Caractéristiques de la découverte implicite :
- Aucune requête explicite ;
- Recommandation proactive, forte place du visuel ;
- Sérendipité algorithmique, l’impression de découvrir « par hasard ».
Limites de l’approche :
- Bulle de filtres et biais de confirmation ;
- Trafic volatil et difficilement prévisible ;
- Risque de manipulation et perte de contrôle par l’utilisateur.

L’impact de la recherche conversationnelle sur le SEO et l’éditorial pour Discover : il faut penser « flux‑first », avec des titres clairs et émotionnels, mais honnêtes, des visuels forts, un rafraîchissement régulier, des signaux d’engagement et une cohérence d’angle éditorial. Le packaging compte autant que le fond, à qualité égale.
Impact de manière plus générale : Un site web qui donne des réponses factuelles n’a plus de raison d’être. Les LLMs, assistés par un Knowledge Graphe qui assure l’ancrage des faits, peuvent répondre directement et de manière plus fiable.
Il faut privilégier les retours utilisateurs, les véritables expériences humaines, ancrées autour d’une marque, de ses entités connexes, sous l’angle d’un persona donné que les systèmes de recommandation pourront raccrocher à des profils type (voir les embeddings utilisateurs)
Le paradoxe de la sérendipité algorithmique
La vraie sérendipité est un hasard heureux. Les flux, eux, calculent ce qui devrait nous surprendre agréablement. L’illusion fonctionne parfois : « c’est exactement ce que je voulais lire », mais elle reste une prédiction inductive. D’où un double enjeu sociotechnique : comment préserver l’ouverture (diversité des points de vue) et limiter la manipulation tout en gardant le plaisir de la découverte ?

Ce que la timeline change pour le SEO (boîte à outils rapide)
Aujourd’hui, les professionnels doivent :
- Adopter une logique « entités + intentions » plutôt que « mots‑clés bruts » ;
- Structurer l’information pour la synthèse : intertitres précis, listes, tableaux, FAQ ;
- Citer et rendre traçables les sources pour nourrir la confiance ;
- Optimiser le packaging de découverte : titres, images, extraits, données fraîches ;
- Mesurer au-delà du clic : satisfaction, temps utile, rétention, récurrence ;
- Préparer des contenus « multi‑destins » : page, réponse conversationnelle, carte Discover.
- Organiser les contenus autour de la marque, de ses valeurs, de ses profils utilisateurs type, d’expérience vécue.
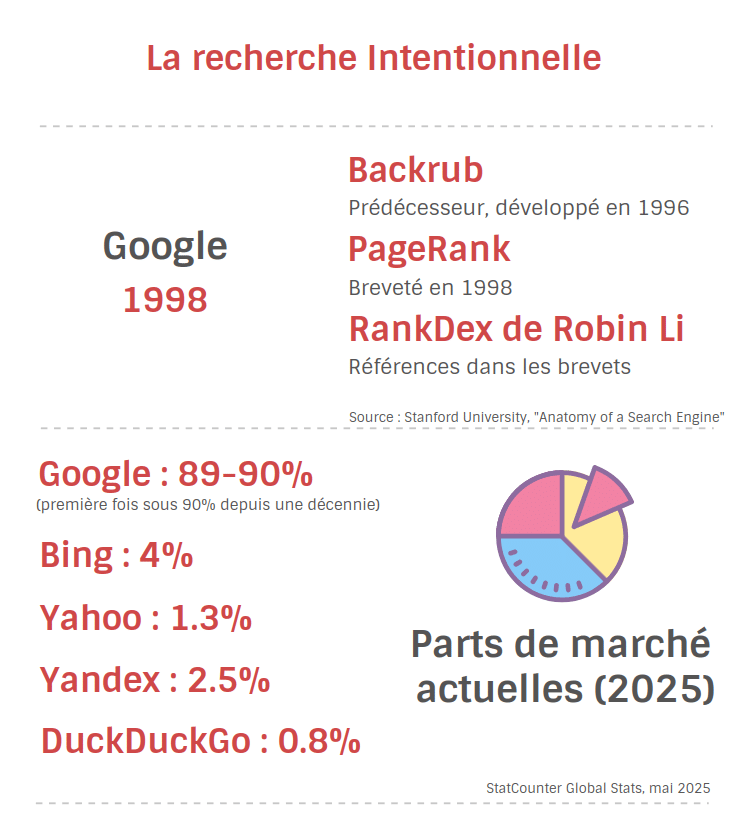
Quelques chiffres
- Part de marché des moteurs dominée par Google autour de 90 % en 2025 ;
- Les AI Overviews sont visibles sur une large part des requêtes en 2024 – Hors UE ;
- Google Discover compte plusieurs centaines de millions d’utilisateurs ;
- Plateformes de recommandation à l’échelle du milliard (TikTok, YouTube, Instagram).
Vers une cinquième étape
On voit poindre une convergence, ou en tout cas un besoin utilisateur : la précision des LLM associée à une vérification temps réel, la transparence des sources et un contrôle utilisateur plus fin sur les flux.
En clair : des réponses fiables, auditables et personnalisables, servies dans une interface conversationnelle fluide.
C’est notamment ce vers quoi va Google, avec ses toutes récentes fonctionnalités de “follow” d’entités, et de “Daily hub”…