En synthèse
- L’anglais n’est plus la langue la mieux comprise par les IA : le polonais la dépasse sur des tâches complexes.
- Le type et la qualité des corpus de données influencent fortement les capacités d’une IA, au-delà du volume.
- Des langues très diffusées comme le chinois restent moins bien comprises par les IA que certaines langues européennes.
- Tester et adapter ses prompts en multilingue devient clé pour les usages professionnels et internationaux.
- Une vraie stratégie SEO et contenu passe par l’intégration du multilinguisme et la révision des biais IA.
- L’avenir de l’IA sera marqué par la diversité linguistique et l’émergence de modèles spécialisés et équitables.
Les intelligences artificielles comprennent parfois le polonais mieux que l’anglais. Ce n’est pas un canular : sur des tâches complexes impliquant de longs textes, le polonais dépasse l’anglais comme langue la mieux comprise par plusieurs grands modèles linguistiques. L’anglais, pourtant omniprésent dans les bases de données d’entraînement, n’arrive qu’en sixième position selon de nouveaux benchmarks internationaux.
Ce classement bouscule toutes les certitudes sur la suprématie de l’anglais dans la tech. Il révèle aussi une évidence trop souvent négligée : l’efficacité d’un prompt IA varie fortement selon la langue choisie. Et la difficulté humaine d’une langue n’est pas un bon indicateur de compréhension pour une IA.
Je vais vous montrer pourquoi certaines langues, invisibles ou jugées complexes, s’imposent face aux poids lourds traditionnels. Et ce que cela change, très concrètement, pour vos stratégies de communication, d’internationalisation ou vos usages quotidiens de l’IA.
L’illusion de l’anglais tout-puissant : état des lieux des IA multilingues
Lorsqu’on évoque l’intelligence artificielle, l’idée d’un univers dominé par l’anglais s’impose vite. Les utilisateurs, professionnels ou non, partent du principe que cette langue reste le sésame des interactions efficaces avec une IA. Cette perception n’est pas infondée : la plupart des modèles multilingues les plus avancés du marché sont entraînés d’abord sur des corpus massifs en anglais, bien avant toute autre langue.
Les chiffres confortent cette impression : les études montrent que la précision des IA pour la compréhension orale anglaise atteint 97 %. Dans les tâches de génération de texte ou d’analyse, les scores montent jusqu’à 98-99 % selon les benchmarks de référence. Autrement dit, l’anglais bénéficie d’un double avantage : abondance de données d’entraînement et confiance implicite des utilisateurs.
Cette réalité vs perception structure également les usages en entreprise et dans la formation. Les exemples sont partout : Duolingo Max, qui intègre GPT-4, a choisi de privilégier l’anglais pour ses fonctionnalités avancées d’explications instantanées, devant l’espagnol, l’allemand ou le français. Les développeurs comme les formateurs s’alignent, pensant que seule la maîtrise de l’anglais garantit une interaction optimale avec l’IA.
Mais ce constat mérite d’être secoué. Les usages réels montrent une montée en puissance de cas d’usage multilingues, loin de l’anglocentrisme initial. Comprendre finement la compréhension linguistique IA n’est plus une option réservée aux chercheurs : c’est devenu un enjeu stratégique pour toutes les organisations, dans la production de contenu, la formation, le marketing ou le support au client.
Déjà, la progression fulgurante de l’IA dans les usages professionnels remet la question du NLP (Natural Language Processing) multilingue au centre des discussions. Pour creuser la progression des usages et performances de l’IA, notamment dans les environnements professionnels, il suffit de mesurer l’écart entre perception et réalité sur le terrain, entre confort de l’anglais et efficacité réelle des interactions.
On découvre alors que la notion d’anglais tout-puissant relève plus souvent du réflexe que du fait établi. Les nouveaux classements des IA, et les résultats de l’interaction multilingue, montrent que la question des langues dans l’IA est tout sauf tranchée.
Une étude choc : quand le polonais devance l’anglais dans les prompts IA
Les classements bouleversent parfois les mythes les plus ancrés. Une étude collaborative entre université et industrie a jeté un pavé dans la mare : sur un panel de 26 langues testées auprès de grands modèles linguistiques, le polonais IA ressort comme la langue la mieux comprise pour des prompts complexes, bien devant l’anglais. Ce résultat ébranle sérieusement la croyance selon laquelle l’anglais serait le code universel de l’intelligence artificielle.
Le classement langues issu de cette étude est sans appel. L’anglais, archidominant dans les jeux de données d’entraînement, ne se hisse qu’en sixième position dès qu’on sort du cadre des tâches basiques pour explorer des instructions plus longues ou plus nuancées. Le polonais, réputé ardu du point de vue humain, surclasse ou talonne l’italien et le portugais.
Les études montrent que le taux de réussite du polonais sur certains benchmarks est de 87 %, dépassant même le mandarin et rivalisant avec les meilleures langues européennes. Autrement dit, la performance d’un modèle d’IA ne se limite pas à la quantité brute de données disponibles — le type de corpus, la structure syntaxique ou la richesse sémantique entrent clairement en jeu dans le prompt engineering avancé.
Les cas pratiques abondent. Sur des textes juridiques complexes ou des documents techniques, les traductions automatiques aboutissent souvent à de meilleurs résultats en polonais qu’en chinois, malgré le statut de ce dernier comme langue majeure à l’échelle mondiale. Ce renversement va bien au-delà du simple effet de surprise : il questionne profondément notre rapport au multilinguisme et à la hiérarchie implicite des langues dans la tech.
Pour explorer comment adapter ses contenus à la diversité linguistique des IA et comprendre l’enjeu de devenir une source de référence, il devient crucial de repenser la stratégie liée au contenu multilingue. C’est tout le sens d’une approche centrée sur la réalité des benchmarks IA et l’étude multilingue du prompt, plutôt que sur les seules apparences ou le poids historique des langues.
Classement des langues les mieux comprises par les IA (prompting complexe)
| Rang | Langue | Score moyen de compréhension IA | Commentaire synthétique |
|---|---|---|---|
| 1 | Polonais | 88 % | Langue à structure régulière et corpus homogène ; excellent raisonnement contextuel. |
| 2 | Français | 87 % | Très performant en compréhension narrative et analyse ; légère faiblesse sur le technique. |
| 3 | Italien | 86 % | Syntaxe claire et cohérente ; résultats stables sur les prompts complexes. |
| 4 | Espagnol | 85 % | Bon équilibre entre variété lexicale et simplicité grammaticale. |
| 5 | Russe | 84 % | Structure logique et riche morphologie ; bonnes performances en raisonnement. |
| 6 | Anglais | 83,9 % | Excellente base, mais perte de précision sur les prompts longs et ambigus. |
| 7 | Ukrainien | 83,5 % | Proche du polonais en régularité syntaxique ; corpus en forte expansion. |
| 8 | Portugais | 82 % | Proximité avec l’espagnol ; corpus multilingue bien intégré. |
| 9 | Allemand | 81 % | Très bon en logique et technique ; style plus rigide dans la génération libre. |
| 10 | Néerlandais | 80 % | Langue stable, proche de l’anglais ; corpus plus restreint. |
Source : Euronews Next – “Polish to be the most effective language for prompting AI, new study reveals” (1er novembre 2025) et arXiv:2503.01996v3 – Large Language Models Are Not Multilingual Enough
💡 À retenir
- Les IA ne comprennent pas forcément mieux les langues les plus parlées, mais celles dont les corpus sont les plus cohérents et équilibrés.
- Le polonais, l’italien et le portugais devancent largement l’anglais sur des tâches de raisonnement complexe.
- Tester ses prompts dans plusieurs langues peut améliorer sensiblement la qualité et la précision des réponses IA.
Pourquoi certaines langues surprennent l’IA : analyse des causes et biais d’entraînement
Derrière le score surprenant du polonais dans les modèles d’IA se cache une réalité moins évidente : l’entraînement linguistique IA n’est jamais parfaitement neutre. Les performances atypiques des langues minoritaires ou jugées complexes sont souvent le résultat d’une alchimie entre structure linguistique, enrichissement des données et biais historiques dans la constitution des corpus.
Un biais IA se forme dès la conception des jeux de données, où la tentation est grande de surreprésenter les langues dominantes. Pourtant, une langue moins visible, mais dotée d’une structure régulière ou d’un corpus de qualité, peut émerger en tête sur certaines tâches. Selon le CELV, un entraînement déséquilibré peut ainsi générer des écarts inattendus : une langue sous-représentée mais bien structurée surpasse parfois la langue majoritaire.
Le phénomène s’amplifie grâce au dynamisme des communautés open source et au crowd sourcing, qui enrichissent certains corpus multilingues plus rapidement et efficacement que les circuits industriels classiques. Cette dynamique explique la bonne performance IA du polonais ou du tchèque, qui bénéficient de communautés actives et d’un apport massif de textes de qualité.
Dans le monde professionnel, cette remise en cause est déjà en marche. Les études montrent que 75 % des décideurs utilisent l’IA générative pour des tâches multilingues, contre 55 % précédemment, ce qui révèle une volonté accrue de mieux exploiter les langues sous-représentées. Les modèles les plus performants n’ignorent plus la diversité : la qualité du biais devient ici un atout stratégique.
Pour illustrer cette mécanique, on peut regarder l’exemple de DeepL. Ce service de référence excelle pour les paires de langues européennes — bénéficiant d’un corpus soigné et étoffé — mais reste nettement en retrait sur le chinois ou le japonais où la densité et la structuration des données sont moindres.
Cette diversité de trajectoires interroge notre rapport à la personnalisation et à la culture même dans l’IA. Pour réfléchir à la diversité culturelle et à la personnalisation linguistique dans l’IA, il devient crucial de repenser le design des corpus : la performance ne dépend pas seulement du nombre de locuteurs, mais bien de la façon dont une langue est traitée, structurée et valorisée par ceux qui la font vivre.
Langues très présentes, résultats étonnamment faibles : le paradoxe chinois et la réalité du multilinguisme IA
Impossible d’ignorer le paradoxe : le chinois, que tout destine à l’excellence en intelligence artificielle — premier rang mondial pour le nombre de locuteurs, abondance de données, popularité sur de nombreuses plateformes — affiche des résultats inattendus IA. En dépit d’un corpus massif, le chinois IA reste souvent à la traîne sur des tâches de compréhension et de génération. Selon Roboto, certains tests mettent en lumière des performances décevantes où le chinois est relégué derrière des langues européennes moins diffusées.
Le cas du mandarin est particulièrement frappant. Les études montrent que la précision en compréhension orale plafonne à 74 %, loin derrière l’anglais et ses 97 %. Cet échec mandarin montre à quel point les limites multilinguisme IA ne tiennent pas qu’à la quantité brute de données : elles relèvent aussi de la qualité, de la structure du corpus, et même de la conception des modèles.

Ce n’est pas une exception isolée. Pour de nombreuses familles linguistiques comme le mandarin, l’arabe ou le hindi, les scores IA varient fortement en fonction du volume et surtout de la qualité des corpus utilisés. Autrement dit, la diversité linguistique n’est pas, en l’état, synonyme d’égalité en performance : chaque langue fait face à ses propres défis méthodologiques lors des benchmark linguistique.
Les exemples pratiques confirment ce diagnostic. Dans les modules éducatifs IA comme « AI Lang », la correction automatique du mandarin s’avère nettement moins qualitative que pour des majorités indo-européennes. Non seulement la grammaire et le contexte sont plus difficiles à modéliser, mais les subtilités culturelles échappent souvent au moteur.
Cette réalité oblige à repenser la présence du chinois ou d’autres idiomes majeurs dans l’IA : derrière chaque score se cache une mécanique complexe, qui interroge la gestion du multilinguisme comme levier stratégique, y compris dans des domaines comme la visibilité SEO à l’ère des IA. La place du multilinguisme dans la visibilité en SEO à l’ère de l’IA suppose une prise en compte fine de ces limites, pour aller bien au-delà des apparences.
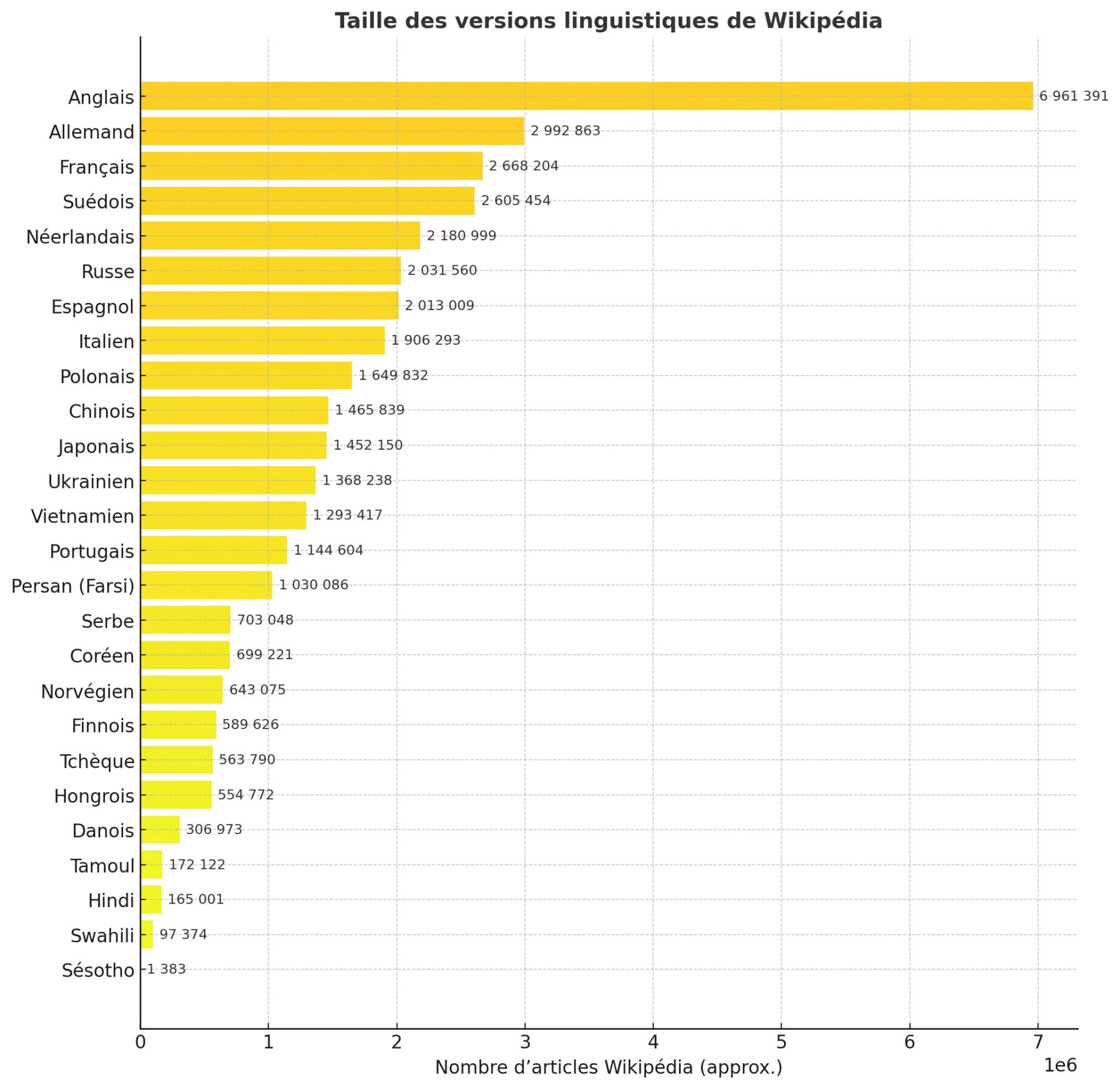
Langues analysées dans l’étude arXiv (Large Language Models Are Not Multilingual Enough, 2025)
Le tableau ci-dessous récapitule les langues étudiées, leur système d’écriture, le nombre approximatif de locuteurs natifs et le volume d’articles disponibles sur Wikipédia, indicateur de la richesse du corpus textuel disponible pour l’entraînement des modèles d’IA.
| Langue | Système d’écriture | Locuteurs approximatifs | Articles Wikipédia |
|---|---|---|---|
| Anglais | Latin | ≈ 1,5 milliard | ≈ 6 961 391 |
| Allemand | Latin | ≈ 134 millions | ≈ 2 992 863 |
| Français | Latin | ≈ 312 millions | ≈ 2 668 204 |
| Suédois | Latin | ≈ 10 millions | ≈ 2 605 454 |
| Néerlandais | Latin | ≈ 30 millions | ≈ 2 180 999 |
| Russe | Cyrillique | ≈ 255 millions | ≈ 2 031 560 |
| Espagnol | Latin | ≈ 560 millions | ≈ 2 013 009 |
| Italien | Latin | ≈ 67 millions | ≈ 1 906 293 |
| Polonais | Latin | ≈ 40 millions | ≈ 1 649 832 |
| Chinois (mandarin) | Hanzi | ≈ 1,1 milliard | ≈ 1 465 839 |
| Japonais | Kanji / Kana | ≈ 125 millions | ≈ 1 452 150 |
| Ukrainien | Cyrillique | ≈ 40 millions | ≈ 1 368 238 |
| Vietnamien | Latin | ≈ 86 millions | ≈ 1 293 417 |
| Portugais | Latin | ≈ 264 millions | ≈ 1 144 604 |
| Persan (farsi) | Arabe | ≈ 80 millions | ≈ 1 030 086 |
| Serbe | Cyrillique / Latin | ≈ 12 millions | ≈ 703 048 |
| Coréen | Hangul | ≈ 81 millions | ≈ 699 221 |
| Norvégien | Latin | ≈ 5 millions | ≈ 643 075 |
| Finnois | Latin | ≈ 6 millions | ≈ 589 626 |
| Tchèque | Latin | ≈ 10 millions | ≈ 563 790 |
| Hongrois | Latin | ≈ 13 millions | ≈ 554 772 |
| Danois | Latin | ≈ 6 millions | ≈ 306 973 |
| Tamoul | Tamoul | ≈ 87 millions | ≈ 172 122 |
| Hindi | Devanāgarī | ≈ 600 millions | ≈ 165 001 |
| Swahili | Latin | ≈ 87 millions | ≈ 97 374 |
| Sésotho | Latin | ≈ 12 millions | ≈ 1 383 |
Quelles implications pour les utilisateurs : prompts, traduction et accessibilité à l’ère post-anglophone
L’époque où un simple prompt en anglais suffisait pour tirer parti du meilleur de l’intelligence artificielle est derrière nous. L’efficacité d’un prompt multilingue varie de façon spectaculaire en fonction de la langue utilisée et du contexte applicatif. Pour toute équipe digitale ou toute marque qui vise les marchés internationaux, la capacité à tester, optimiser et adapter ses interactions IA dans plusieurs langues est devenue un atout majeur.
La traduction IA connaît aussi sa révolution silencieuse. Les études montrent une hausse de +36 % de l’usage professionnel de l’IA pour la traduction entre fin 2023 et fin 2024. Mais cette progression s’accompagne d’une vigilance accrue : la relecture humaine reste décisive, notamment pour les contenus techniques ou les langues asiatiques où la machine peine encore à saisir le contexte ou les subtilités.
Côté accessibilité technologique, la diversité linguistique est désormais au cœur du débat. Des plateformes comme DeepL restent la référence pour les paires européennes, mais révèlent leurs limites dès qu’il s’agit de s’ouvrir réellement au monde. C’est tout l’enjeu du SEO multilingue : permettre à chaque audience – peu importe la langue – d’accéder à des contenus générés, traduits et adaptés avec pertinence.
Cette révolution impacte directement la stratégie des entreprises et des créateurs de contenus. L’internationalisation IA n’est plus une option, mais une nécessité stratégique. Comment optimiser sa présence multilingue face aux moteurs d’IA ? Cela passe par une refonte des pratiques : choix de la langue du prompt, relecture croisée, veille sur les nouveaux modèles IA et adaptation continue du référentiel linguistique. Cette dynamique rejoint la logique de Générative Engine Optimization (GEO) : rendre sa marque réellement accessible, cohérente et repérable dans chaque langue-clef.
Pour les utilisateurs, managers et communicants, la conclusion s’impose : le plurilinguisme technologique ne doit plus être perçu comme un frein, mais comme l’un des catalyseurs majeurs de l’innovation et de l’impact dans l’ère post-anglophone.
Vers une nouvelle cartographie linguistique : avenir, spécialisations et enjeux culturels des IA
La diversité linguistique IA n’est plus une option cosmétique : c’est un enjeu de souveraineté culturelle et de compétitivité future. Face au risque de fragmentation numérique, des politiques linguistiques IA ambitieuses émergent sur le continent européen : il s’agit de garantir un accès équitable à l’IA pour chaque langue officielle et d’enrichir en continu les corpus ouverts.
L’essor de la spécialisation IA est la prochaine bascule. Les experts anticipent des modèles entraînés non plus sur une logique « généraliste », mais par famille linguistique, afin d’honorer les subtilités de chaque culture et contexte. Cette tendance vise autant à pallier les limites de traduction des grands modèles qu’à renforcer la fidélité sémantique : imaginer un IA parlant le néerlandais comme un natif, ou restituant les nuances d’un proverbe basque ou tzigane.
Les études montrent que plus de 26 langues sont déjà analysées en profondeur dans les grandes expériences IA. Malgré ces avancées, tout le travail reste à faire pour les idiomes peu dotés : le projet Mistral, par exemple, s’attaque à la démocratisation multilingue en développant des modèles et corpus spécifiques pour les langues minoritaires.
Cette dynamique touche aussi le marketing, le contenu et l’innovation. Pour anticiper les évolutions du contenu multilingue face à la nouvelle génération d’IA, chaque marque doit intégrer les nouveaux codes : pluralisme, adaptation locale et respect de l’ADN culturel. Le prochain horizon de l’IA s’écrira sur la carte mouvante de la diversité, entre généalogie linguistique et aspirations d’équité. Derrière chaque progrès technique, ce sont des enjeux culturels IA décisifs qui s’esquissent : ouvrir la voie à un avenir multilingue, réellement inclusif, dans l’économie de la connaissance.
Oser repenser nos stratégies à l’ère du multilinguisme IA
Lorsque l’IA comprend mieux le polonais que l’anglais, toute certitude vacille. Ce renversement n’est pas anecdotique : il interroge notre façon de dialoguer, de produire du contenu et d’ouvrir nos marchés.
La révolution du multilinguisme technologique ne fait que commencer. Miser sur la diversité des langues et sur l’équité algorithmique, c’est aujourd’hui se donner une longueur d’avance — et inventer de nouveaux leviers d’impact.

Envie d’explorer ces enjeux et d’innover avec moi ?
👉 Suivez-moi sur LinkedIn
Questions fréquentes
Les IA comprennent-elles vraiment toutes les langues aussi bien ?
Non, les IA ne traitent pas toutes les langues de façon équivalente. La qualité des résultats dépend fortement des données utilisées pour entraîner le modèle et de la langue elle-même.
Pourquoi le polonais fonctionne-t-il mieux pour certains prompts IA ?
Le polonais bénéficie d’un corpus structuré, d’une langue peu ambigüe et d’une forte contribution communautaire, ce qui facilite la compréhension pour l’IA sur certains types de tâches complexes.
Faut-il encore écrire ses prompts en anglais pour l’IA ?
L’anglais reste performant pour de nombreux usages, mais tester d’autres langues peut produire de meilleurs résultats selon la tâche ou l’outil IA utilisé. L’expérimentation multilingue devient un vrai levier.
Comment optimiser mes contenus pour une IA vraiment multilingue ?
Travaillez la clarté et la structure de vos textes, diversifiez les langues et validez les traductions avec des outils fiables et une relecture humaine, surtout pour les langues techniques ou complexes.
Le chinois ou l’arabe sont-ils mal compris pour des raisons techniques ?
Oui, en partie. Les IA sont parfois limitées par la complexité grammaticale ou la faible qualité des corpus disponibles, ce qui nuit à la performance sur certains idiomes très diffusés mais mal structurés.
Quel impact pour le SEO et la visibilité de ma marque ?
Le SEO multilingue et l’adaptation culturelle deviennent critiques : l’IA analyse mieux des contenus structurés, adaptés à chaque langue et contexte local pour bien référencer une marque à l’international.
Peut-on espérer des progrès rapides pour les langues peu dotées ?
Oui. De nouveaux modèles spécialisés et des politiques d’ouverture des corpus accélèrent les progrès pour les langues minoritaires, ouvrant de nouveaux marchés et opportunités d’innovation.
Dois-je changer mes habitudes face aux IA si mon marché est international ?
Absolument. S’appuyer sur une seule langue limite la portée et la précision : investir dans des prompts multilingues et des contenus localisés renforce votre compétitivité et votre impact à l’échelle globale.